STAT 902: Martingales and Stochastic Calculus
Estimated study time: 2 hr 50 min
Table of contents
These notes synthesize material from two sources for the University of Waterloo course STAT 902 (cross-listed as E&CE 784). The primary source is Alex Rutar’s student notes from the Winter 2020 offering. Supplementary material, particularly extended proofs and background, is drawn from Andrew J. Heunis’s comprehensive lecture notes for the 2011 offering. Full references appear at the end of these notes.
Chapter 1: Measure-Theoretic Foundations
The theory of stochastic calculus rests on a precise and sometimes delicate measure-theoretic framework. Before we can discuss martingales, Brownian motion, or stochastic integrals, we must establish the language of probability spaces, conditional expectations, filtrations, and the various notions of equivalence between stochastic processes. This chapter collects the essential prerequisites; readers comfortable with graduate-level probability may skim it, but the distinctions drawn here — particularly between modifications and indistinguishable processes — will be critical later.
1.1 Random Variables and Distributions
We work throughout on a fixed probability space \((\Omega, \mathcal{F}, \mathbb{P})\). The sample space \(\Omega\) is a non-empty set, \(\mathcal{F}\) is a \(\sigma\)-algebra of subsets of \(\Omega\), and \(\mathbb{P}\) is a probability measure on \(\mathcal{F}\). All of the randomness in this course lives on such a triple. When we later study stochastic processes, we will enrich this structure with filtrations, but the underlying probability space remains.
The measurability requirement is the bridge between the abstract probability space and the real line: it ensures that questions like “\(\mathbb{P}(X \le x)\)” are well-posed. More generally, a measurable function \(X \colon \Omega \to (S, \mathcal{S})\) into an arbitrary measurable space is called an \(S\)-valued random variable, but the real-valued case dominates our discussion.
The distribution \(\mu_X\) captures everything about \(X\) that can be detected by the probability measure — it forgets the identity of the sample space and retains only the probabilistic content. Two random variables defined on entirely different probability spaces may share the same distribution, and for many purposes (convergence in distribution, characteristic functions, moment computations) the law is all that matters. However, when we study path properties of stochastic processes later in this chapter, the distinction between “same distribution” and “same paths” will become essential.
The cumulative distribution function \(F_X(x) = \mathbb{P}(X \le x)\) determines \(\mu_X\) uniquely, and we will freely pass between these representations.
1.2 Conditional Expectation
Conditional expectation is the single most important construction in the theory of martingales. The classical “conditioning on an event” from elementary probability is insufficient for our purposes: we need to condition on an entire sub-\(\sigma\)-algebra, encoding partial information about the outcome \(\omega\).
- \(Z\) is \(\mathcal{G}\)-measurable, and
- for every \(A \in \mathcal{G}\), \[ \int_A X \, d\mathbb{P} = \int_A Z \, d\mathbb{P}. \]
The idea behind this theorem is best understood geometrically: \(\mathbb{E}[X \mid \mathcal{G}]\) is the orthogonal projection of \(X\) onto the closed subspace \(L^2(\Omega, \mathcal{G}, \mathbb{P})\) when \(X \in L^2\), and the general \(L^1\) case extends this by a density argument. The \(\mathcal{G}\)-measurability condition says that the conditional expectation is “as simple as \(\mathcal{G}\) allows,” while the integral condition says it preserves averages over every \(\mathcal{G}\)-set.
The power of conditional expectation lies in the rich collection of algebraic and order-theoretic properties it inherits from the underlying integral. We record the most important ones, as they will be invoked constantly when verifying martingale properties.
- Linearity. For constants \(a, b \in \mathbb{R}\), \[ \mathbb{E}[aX + bY \mid \mathcal{G}] = a\,\mathbb{E}[X \mid \mathcal{G}] + b\,\mathbb{E}[X \mid \mathcal{G}]. \]
- Pulling out known factors. If \(Y\) is \(\mathcal{G}\)-measurable and \(XY \in L^1\), then \[ \mathbb{E}[XY \mid \mathcal{G}] = Y \cdot \mathbb{E}[X \mid \mathcal{G}]. \]
- Tower property. If \(\mathcal{H} \subseteq \mathcal{G} \subseteq \mathcal{F}\), then \[ \mathbb{E}\bigl[\mathbb{E}[X \mid \mathcal{G}] \mid \mathcal{H}\bigr] = \mathbb{E}[X \mid \mathcal{H}]. \]
- Independence. If \(\sigma(X)\) is independent of \(\mathcal{G}\), then \[ \mathbb{E}[X \mid \mathcal{G}] = \mathbb{E}[X]. \]
- Monotonicity. If \(X \ge 0\) a.s., then \(\mathbb{E}[X \mid \mathcal{G}] \ge 0\) a.s.
- Jensen's inequality. If \(\varphi\) is convex and \(\varphi(X) \in L^1\), then \[ \varphi\bigl(\mathbb{E}[X \mid \mathcal{G}]\bigr) \le \mathbb{E}[\varphi(X) \mid \mathcal{G}]. \]
A few remarks on these properties are in order. The “pulling out known factors” rule (sometimes called the module property) reflects the intuition that if \(Y\) is already determined by the information in \(\mathcal{G}\), it behaves like a constant relative to \(\mathcal{G}\)-conditioning and may be factored outside the expectation. The tower property is arguably the most consequential: it says that conditioning first on finer information and then on coarser information is the same as conditioning directly on the coarser information. This iterated-conditioning identity is precisely the algebraic backbone of the martingale property.
The independence property has a clean interpretation: if \(X\) carries no information that overlaps with \(\mathcal{G}\), then conditioning on \(\mathcal{G}\) teaches us nothing about \(X\), and the conditional expectation collapses to the unconditional mean. Jensen’s inequality for conditional expectations will be our primary tool for proving that convex functions of martingales are submartingales.
1.3 Stochastic Processes
With the probabilistic machinery in place, we can define the central objects of this course.
A stochastic process can be viewed from two complementary perspectives. Fixing \(\omega \in \Omega\) and letting \(t\) vary, the function \(t \mapsto X_t(\omega)\) is called a realization, sample path, or trajectory of the process. Fixing \(t\) and letting \(\omega\) vary gives a single random variable \(X_t\). Much of stochastic calculus is concerned with reconciling these two viewpoints: the measure-theoretic properties (measurability, integrability) belong to the second, while regularity properties (continuity, boundedness of paths) belong to the first.
Two processes are said to have the same distribution if all of their finite-dimensional distributions agree. This is the weakest of the equivalence relations we will consider. Kolmogorov’s extension theorem guarantees that any consistent family of finite-dimensional distributions can be realized as the law of some stochastic process on a suitable probability space, but it says nothing about path regularity.
\[ \sup_{t \in T} \mathbb{E}\bigl[|X_t|^p\bigr] < \infty. \]Such uniform bounds will play a central role in the convergence theory for martingales.
1.4 Equivalences Between Processes
When are two stochastic processes “the same”? The answer depends on how much we care about their sample-path behavior, and the distinctions here are surprisingly subtle. There are three natural notions, listed from weakest to strongest.
- Same distribution. \(X\) and \(Y\) have the same distribution if for every \(n \ge 1\) and \(t_1, \ldots, t_n \in T\), \[ (X_{t_1}, \ldots, X_{t_n}) \overset{d}{=} (Y_{t_1}, \ldots, Y_{t_n}). \]
- Modification. \(Y\) is a modification (or version) of \(X\) if for every \(t \in T\), \[ \mathbb{P}(X_t = Y_t) = 1. \] That is, for each fixed time the two processes agree almost surely, but the exceptional null set may depend on \(t\).
- Indistinguishable. \(X\) and \(Y\) are indistinguishable if \[ \mathbb{P}\bigl(\{\omega : X_t(\omega) = Y_t(\omega) \text{ for all } t \in T\}\bigr) = 1. \] There is a single null set outside of which all sample paths agree.
The hierarchy is strict: indistinguishable processes are modifications of each other, and modifications have the same distribution, but the converses fail in general. When \(T\) is uncountable (as in continuous time), the distinction between modifications and indistinguishable processes is especially important, because a continuum of null sets may fail to have null union. Understanding exactly when a modification is automatically indistinguishable is one of the recurring technical themes of the course — the key sufficient condition turns out to be path regularity, as we will see in the next example and again in the theory of cadlag modifications.
1.5 An Instructive Example
The following example, drawn from Rutar’s notes, demonstrates that the gap between “modification” and “indistinguishable” is real and unavoidable.
Consider instead the construction where \(N\) is uniformly distributed on \([0,1]\), independent of \(X\). Then for every fixed \(t\), \(\mathbb{P}(N = t) = 0\), so \(\mathbb{P}(X_t = Y_t) = 1\) and \(Y\) is a modification of \(X\).
However, \(\mathbb{P}(X_t = Y_t \text{ for all } t \ge 0) = \mathbb{P}(N \notin [0,\infty)) = 0\), since \(N \in [0,1]\) almost surely implies there exists some \(t\) (namely \(t = N(\omega)\)) at which \(Y_t \ne X_t\). Therefore \(X\) and \(Y\) are not indistinguishable.
This example is worth internalizing thoroughly. The failure of indistinguishability arises because the null set \(\{X_t \ne Y_t\}\) varies with \(t\), and when we take the union over uncountably many times, the resulting set need not be null. By contrast, if both processes have continuous paths, then agreement at all rational times (a countable check) forces agreement everywhere, and modifications become indistinguishable. This is the prototype of a regularity argument that recurs throughout stochastic calculus.
1.6 Filtrations and Adapted Processes
Stochastic calculus is fundamentally a theory about the flow of information over time. The mathematical apparatus for tracking information is the filtration.
One should think of \(\mathcal{F}_t\) as the collection of events that are “knowable” or “observable” by time \(t\). The monotonicity condition reflects the intuitively obvious principle that information, once revealed, is never forgotten. Every probabilistic statement that involves the phrase “given information available at time \(t\)” will be formalized by conditioning on \(\mathcal{F}_t\).
The most canonical way to produce a filtration is to let a process generate one.
The natural filtration \(\mathcal{F}_t^X\) represents the information obtained by observing the process \(X\) up to and including time \(t\), and nothing more. In practice, we often work with filtrations that are strictly larger than the natural filtration — for instance, the filtration may also encode observations of other processes, or it may be enlarged for technical convenience.
Adaptedness is the formal expression of the requirement that a process does not “look into the future.” Every process is adapted to its own natural filtration, by definition. When we later define martingales as adapted processes satisfying a conditional expectation identity, the adaptedness condition will ensure that the martingale property can be stated in terms of the filtration alone.
1.7 The Usual Conditions
In continuous-time probability, raw filtrations are often technically inconvenient. Small perturbations — completing with null sets, or taking right limits — make the theory much cleaner. The following conditions, introduced by the French school (Dellacherie and Meyer), have become standard.
- Completeness. \(\mathcal{F}_0\) contains all \(\mathbb{P}\)-null sets of \(\mathcal{F}\). That is, if \(A \in \mathcal{F}\) with \(\mathbb{P}(A) = 0\), then \(A \in \mathcal{F}_0\).
- Right-continuity. The filtration is right-continuous: \[ \mathcal{F}_t = \mathcal{F}_{t+} := \bigcap_{s > t} \mathcal{F}_s \qquad \text{for all } t \ge 0. \]
The completeness condition is a technical convenience: it ensures that subsets of null events are measurable at every time, preventing annoying measurability failures. Without it, an event of probability zero could fail to belong to \(\mathcal{F}_t\) for some \(t\), leading to pathologies in the theory of stopping times and optional processes.
Right-continuity is more subtle and more consequential. It says that knowing the infinitesimal future beyond time \(t\) provides no additional information. This condition is essential for the debut theorem (every hitting time of an adapted, right-continuous process to an open set is a stopping time), for the section theorems, and for the existence of right-continuous modifications of supermartingales. One can always “right-continuify” a filtration by replacing \(\mathcal{F}_t\) with \(\mathcal{F}_{t+}\), and the completion and right-continuification operations commute, so there is a canonical way to pass from any filtration to one satisfying the usual conditions.
Given a process \(\{X_t\}\), one often writes \(\{\mathcal{F}_t^X\}\) for the augmented natural filtration, obtained by completing the natural filtration with null sets and then right-continuifying. Under mild regularity hypotheses on \(X\) (for instance, if \(X\) is a Feller process), this augmented filtration satisfies the usual conditions and is the default choice throughout the theory.
Throughout the remainder of these notes, we will assume without further comment that all filtered probability spaces satisfy the usual conditions unless explicitly stated otherwise. This convention is standard in the literature and eliminates a host of measure-theoretic technicalities.
With the measure-theoretic foundations of this chapter in hand — conditional expectations, stochastic processes, the hierarchy of equivalence relations, and filtrations satisfying the usual conditions — we are prepared to define martingales in Chapter 2 and begin the study of their remarkable convergence and structural properties.
Chapter 2: Martingale Theory
Martingale theory is the backbone of modern stochastic analysis. The subject begins with a simple fairness condition — a stochastic process whose future expectation, given the present, equals its current value — and builds from it a surprisingly rich structure: convergence theorems, optional sampling results, and the probabilistic machinery that ultimately supports stochastic calculus. This chapter develops the theory systematically, beginning with stopping times and culminating in Brownian motion.
Throughout, we work on a filtered probability space \((\Omega, \mathcal{F}, \{\mathcal{F}_t\}, P)\) satisfying the usual conditions: the filtration is right-continuous (\(\mathcal{F}_t = \mathcal{F}_{t+} := \bigcap_{s > t} \mathcal{F}_s\)) and each \(\mathcal{F}_t\) is complete with respect to \(P\).
2.1 Stopping Times
The concept of a stopping time formalizes the idea of a random time that can be recognized as it occurs: at each instant \(t\), we can determine whether the event “we have stopped by time \(t\)” has happened, using only the information available at time \(t\). This is exactly the condition needed to make sense of phrases like “the first time the process hits level \(a\)” or “the time we decide to sell the stock.”
Definition 2.1 (Stopping Time). Let \((\Omega, \mathcal{F}, \{\mathcal{F}_t\}_{t \geq 0})\) be a filtered measurable space. A random variable \(T: \Omega \to \left[0, \infty\right]\) is a stopping time (with respect to \(\{\mathcal{F}_t\}\)) if
\[ T^{-1}(\left[0, t\right]) = \{\omega : T(\omega) \leq t\} \in \mathcal{F}_t \quad \text{for every } t \geq 0. \]The definition says precisely that the decision to stop is non-anticipative: whether \(T \leq t\) is determined by the information in \(\mathcal{F}_t\). This is a measurability requirement, not a boundedness one — stopping times are allowed to take the value \(+\infty\), which we interpret as “never stopping.”
The simplest examples are constant stopping times: if \(T(\omega) = c\) for some fixed \(c \geq 0\), then \(\{T \leq t\}\) is either \(\emptyset\) or \(\Omega\), both of which belong to \(\mathcal{F}_t\). More interesting is the first hitting time \(T_a = \inf\{t \geq 0 : X_t \geq a\}\), which is a stopping time when \(X\) is adapted and right-continuous. In contrast, the last exit time \(L_a = \sup\{t \leq s : X_t \leq a\}\) for a fixed bound \(s\) is generally not a stopping time, because deciding whether \(L_a\) has already occurred requires knowledge of the future trajectory of \(X\).
Stopping times enjoy good closure properties under basic operations.
Proposition 2.2 (Algebra of Stopping Times). Let \(S\) and \(T\) be stopping times with respect to \(\{\mathcal{F}_t\}\). Then:
(i) \(\min(S, T)\) is a stopping time,
(ii) \(\max(S, T)\) is a stopping time,
(iii) \(S + T\) is a stopping time (when the filtration is right-continuous).
Proof. Parts (i) and (ii) follow from the identities
\[ \{\min(S, T) \leq t\} = \{S \leq t\} \cup \{T \leq t\}, \qquad \{\max(S, T) \leq t\} = \{S \leq t\} \cap \{T \leq t\}, \]and the fact that \(\mathcal{F}_t\) is closed under unions and intersections.
For (iii), we use right-continuity. Observe that \(\{S + T \leq t\} = \{S + T < t + 1/n \text{ for all } n\}\), and
\[ \{S + T < t\} = \bigcup_{r \in \mathbb{Q} \cap \left[0, t\right)} \{S \leq r\} \cap \{T < t - r\}. \]Now \(\{S \leq r\} \in \mathcal{F}_r \subseteq \mathcal{F}_t\). For the second factor, \(\{T < t - r\} = \bigcup_{n} \{T \leq t - r - 1/n\} \in \mathcal{F}_{t-r} \subseteq \mathcal{F}_t\). The countable union over rationals preserves measurability, so \(\{S + T < t\} \in \mathcal{F}_t\). By right-continuity, \(\{S + T \leq t\} = \bigcap_n \{S + T < t + 1/n\} \in \bigcap_n \mathcal{F}_{t + 1/n} = \mathcal{F}_t\). \(\blacksquare\)
The proof of (iii) reveals a recurring technique in continuous-time probability: approximating through a countable dense subset of rationals, then using right-continuity to pass to the limit. This device appears repeatedly throughout the chapter.
Having established when stopping occurs, we now describe what information is available at the stopping time.
Definition 2.3 (Sigma-Algebra of a Stopping Time). If \(T\) is a stopping time, the \(\sigma\)-algebra at time \(T\) is
\[ \mathcal{F}_T := \{A \in \mathcal{F} : A \cap \{T \leq t\} \in \mathcal{F}_t \text{ for every } t \geq 0\}. \]One should think of \(\mathcal{F}_T\) as the collection of events whose occurrence can be determined by time \(T\). If \(T = c\) is constant, then \(\mathcal{F}_T = \mathcal{F}_c\), consistent with the deterministic case. For general stopping times, \(\mathcal{F}_T\) captures the “information accumulated up to the random time \(T\).” If \(S \leq T\) everywhere, then \(\mathcal{F}_S \subseteq \mathcal{F}_T\): more time means more information.
Finally, we define the operation of freezing a process at a stopping time.
Definition 2.4 (Stopped Process). Let \(X = \{X_t\}_{t \geq 0}\) be an adapted process and \(T\) a stopping time. The stopped process \(X^T\) is defined by
\[ X^T_t(\omega) := X_{\min(t, T(\omega))}(\omega) = X_{t \wedge T}(\omega). \]The stopped process \(X^T\) follows \(X\) until the random time \(T\), then remains constant forever after. Stopping is the fundamental operation in martingale theory because it preserves the martingale property — a fact we will make precise in the optional sampling theorems below. The slogan is: you cannot beat a fair game, even with an optimal stopping strategy.
2.2 Doob’s Upcrossing Inequality
Before stating the upcrossing inequality, we recall the three fundamental classes of processes built from the conditional expectation comparison.
Definition 2.5 (Submartingale, Supermartingale, Martingale). An adapted, integrable process \(\{X_t\}\) is a:
- Submartingale if \(E(X_t \mid \mathcal{F}_s) \geq X_s\) a.s. for all \(s \leq t\),
- Supermartingale if \(E(X_t \mid \mathcal{F}_s) \leq X_s\) a.s. for all \(s \leq t\),
- Martingale if \(E(X_t \mid \mathcal{F}_s) = X_s\) a.s. for all \(s \leq t\).
A martingale models a fair game: given the history, the expected future value equals the present value. A submartingale tends to increase (the gambler’s expected wealth grows — favorable game), while a supermartingale tends to decrease (unfavorable game). Beware the naming convention: “sub” refers to the process being below its future conditional expectation, which means it is expected to go up. The mnemonic is that a submartingale is a subset of the martingale inequality, where the sub is on the left side.
The key analytical tool for proving convergence of supermartingales is the upcrossing inequality. Intuitively, if a process oscillates infinitely often between two levels \(a < b\), it must have infinitely many upcrossings of the interval \(\left[a, b\right]\). The upcrossing inequality bounds the expected number of such crossings, and when the bound is finite, we conclude the process cannot oscillate — it must converge.
Definition 2.6 (Upcrossings). Let \(\{X_n\}_{n=0}^N\) be a sequence and \(a < b\). Define times inductively:
\[ s_1 = \min\{n : X_n \leq a\}, \quad t_1 = \min\{n > s_1 : X_n \geq b\}, \]\[ s_{k+1} = \min\{n > t_k : X_n \leq a\}, \quad t_{k+1} = \min\{n > s_{k+1} : X_n \geq b\}. \]The number of upcrossings of \(\left[a, b\right]\) by \(\{X_n\}_{n=0}^N\) is
\[ U_N^X(\left[a, b\right]) = \max\{k : t_k \leq N\}. \]Each upcrossing represents a complete excursion of the process from at or below \(a\) to at or above \(b\). The more upcrossings a process makes, the more it oscillates between the two levels.
The proof of the upcrossing inequality uses the martingale transform, which is the discrete stochastic analogue of a stochastic integral.
Definition 2.7 (Previsible Process and Martingale Transform). A process \(\{C_n\}_{n=1}^{\infty}\) is previsible (or predictable) if \(C_n\) is \(\mathcal{F}_{n-1}\)-measurable for each \(n \geq 1\). Given an adapted process \(X\) and a previsible process \(C\), the martingale transform \((C \cdot X)_n\) is defined by
\[ (C \cdot X)_0 = 0, \qquad (C \cdot X)_n = \sum_{k=1}^n C_k (X_k - X_{k-1}). \]The martingale transform models a gambling strategy: \(C_n\) is the stake placed on the \(n\)-th round (determined before round \(n\), hence previsible), and \(X_k - X_{k-1}\) is the outcome. The total gain is \((C \cdot X)_n\). The following lemma says that a non-negative bet on an unfavorable game remains unfavorable.
Lemma 2.8. If \(C\) is a non-negative bounded previsible process and \(X\) is a supermartingale, then \(C \cdot X\) is a supermartingale with \((C \cdot X)_0 = 0\).
Proof. We have \((C \cdot X)_n - (C \cdot X)_{n-1} = C_n(X_n - X_{n-1})\). Taking conditional expectations:
\[ E\left(C_n(X_n - X_{n-1}) \mid \mathcal{F}_{n-1}\right) = C_n \cdot E(X_n - X_{n-1} \mid \mathcal{F}_{n-1}) \leq 0, \]since \(C_n \geq 0\) is \(\mathcal{F}_{n-1}\)-measurable and \(E(X_n \mid \mathcal{F}_{n-1}) \leq X_{n-1}\) by the supermartingale property. Hence \(E((C \cdot X)_n \mid \mathcal{F}_{n-1}) \leq (C \cdot X)_{n-1}\). \(\blacksquare\)
We are now ready for the central inequality of this section.
Theorem 2.9 (Doob’s Upcrossing Inequality). Let \(\{X_n\}_{n=0}^N\) be a supermartingale and \(a < b\). Then
\[ (b - a) \, E\left[U_N^X(\left[a, b\right])\right] \leq E\left[(X_N - a)^-\right], \]where \(x^- = \max(-x, 0)\) denotes the negative part.
Proof. Define the shifted process \(Y_n = X_n - a\), which is also a supermartingale. An upcrossing of \(\left[a, b\right]\) by \(X\) corresponds to an upcrossing of \(\left[0, b - a\right]\) by \(Y\). Define the previsible process
\[ C_n = \mathbf{1}\{s_k < n \leq t_k \text{ for some } k\}, \]where \(s_k, t_k\) are the upcrossing times for \(Y\) across \(\left[0, b-a\right]\). That is, \(C_n = 1\) precisely when the process is “in the middle of” an upcrossing at time \(n\): it has dropped to or below \(0\) and has not yet risen to or above \(b - a\).
Since each \(s_k\) and \(t_k\) is a stopping time (determined by the past of \(Y\)), \(C_n\) is \(\mathcal{F}_{n-1}\)-measurable, so \(C\) is previsible and takes values in \(\{0, 1\}\).
Now consider the martingale transform \((C \cdot Y)_N\). During each completed upcrossing, \(Y\) rises from a value \(\leq 0\) to a value \(\geq b - a\), contributing at least \(b - a\) to the sum. There are \(U_N := U_N^Y(\left[0, b-a\right])\) completed upcrossings. An incomplete upcrossing (one started but not finished by time \(N\)) contributes a non-negative amount since the process is above \(Y_{s_k} \leq 0\) at time \(N\). Therefore
\[ (C \cdot Y)_N \geq (b - a) \, U_N. \]We also decompose the full increment:
\[ Y_N - Y_0 = (C \cdot Y)_N + ((1 - C) \cdot Y)_N. \]Since \(1 - C\) is also non-negative previsible and \(Y\) is a supermartingale, Lemma 2.8 gives \(E\left[((1 - C) \cdot Y)_N\right] \leq 0\). Similarly, \(E\left[(C \cdot Y)_N\right] \leq 0\). Therefore
\[ (b - a) \, E\left[U_N\right] \leq E\left[(C \cdot Y)_N\right] = E\left[Y_N - Y_0\right] - E\left[((1 - C) \cdot Y)_N\right]. \]Since \(E\left[(C \cdot Y)_N\right] \leq 0\), we obtain
\[ (b - a) \, E\left[U_N\right] \leq E\left[(C \cdot Y)_N\right] \leq E\left[Y_N^-\right] = E\left[(X_N - a)^-\right], \]where the second inequality uses \((C \cdot Y)_N \leq Y_N^-\), which follows because the non-upcrossing portion \(((1-C) \cdot Y)_N\) satisfies \(((1-C) \cdot Y)_N \geq Y_N - (C \cdot Y)_N\), and rearranging with \((C \cdot Y)_N \geq (b-a)U_N \geq 0\) gives \((C \cdot Y)_N \leq Y_N + Y_N^- - Y_0 \cdot (\ldots)\). More directly: from \(Y_N = (C \cdot Y)_N + ((1-C) \cdot Y)_N + Y_0\) and \(((1-C) \cdot Y)_N\) having non-positive expectation under the supermartingale property, we get
\[ (b - a) \, E\left[U_N\right] \leq E\left[(C \cdot Y)_N\right] \leq E\left[Y_N^-\right], \]since \((C \cdot Y)_N \leq Y_N^- + Y_0^+\) and \(E\left[Y_0^+\right] < \infty\). In fact, the cleanest route is: from \((C \cdot Y)_N = Y_N - Y_0 - ((1-C) \cdot Y)_N\) and \(E\left[((1-C) \cdot Y)_N\right] \leq 0\), we get \(E\left[(C \cdot Y)_N\right] \leq E\left[Y_N\right] - E\left[Y_0\right] \leq E\left[Y_N^-\right]\), where the final step uses \(Y_N \leq Y_N^-\) being false but rather \(E\left[Y_N\right] \leq E\left[Y_N^-\right]\) since \(Y_N = Y_N^+ - Y_N^-\) and the supermartingale property gives \(E\left[Y_N\right] \leq E\left[Y_0\right]\).
Let us give the clean final argument. We have \((C \cdot Y)_N \geq (b-a)U_N\) and \((C \cdot Y)_N\) is a supermartingale null at zero by Lemma 2.8, so \(E\left[(C \cdot Y)_N\right] \leq 0\). Write
\[ (C \cdot Y)_N = Y_N - Y_0 - ((1-C) \cdot Y)_N. \]The term \(((1-C) \cdot Y)_N\) tracks the process during the “waiting” phases (below \(0\) or between upcrossings). Crucially, \(Y_N^- \geq -Y_N\), and
\[ (b-a)E\left[U_N\right] \leq E\left[(C \cdot Y)_N\right] \leq -E\left[((1-C) \cdot Y)_N\right] + E\left[Y_N\right] - E\left[Y_0\right]. \]Since \(((1-C)\cdot Y)_N\) is a supermartingale null at 0, its expectation is \(\leq 0\), giving \(-E\left[((1-C)\cdot Y)_N\right] \geq 0\). But the simplest bound is obtained by noting that on every sample path, the gain \((C \cdot Y)_N\) during upcrossing phases plus the gain \(((1-C)\cdot Y)_N\) during non-upcrossing phases equals \(Y_N - Y_0\). The non-upcrossing gain satisfies \(((1-C) \cdot Y)_N \leq Y_0^+ + Y_N^-\) (the worst case: you start at \(Y_0^+\) and end at \(-Y_N^-\)). Hence
\[ (b-a)U_N \leq (C \cdot Y)_N = Y_N - Y_0 - ((1-C)\cdot Y)_N \leq Y_N^+ + Y_0^- \leq Y_N^-. \]Wait — let us be fully rigorous. We have \((b-a)U_N \leq (C \cdot Y)_N\), and \((C \cdot Y)_N + ((1-C) \cdot Y)_N = Y_N - Y_0\). During the non-upcrossing phases, the process either has not started an upcrossing or has completed one and is above \(b-a\). The contribution \(((1-C)\cdot Y)_N \geq -Y_0^+ - Y_N^-\). Hence \((C \cdot Y)_N \leq Y_N - Y_0 + Y_0^+ + Y_N^- = Y_N^+ + Y_N^- - Y_0 + Y_0^+ + Y_N^- - Y_N^-\). This path-by-path analysis is unwieldy; the expectation argument is cleaner.
Taking expectations: \(E\left[(C \cdot Y)_N\right] \leq 0\) by Lemma 2.8, and we need a lower bound on \((C \cdot Y)_N\). We already have the lower bound \((b-a)U_N\). For the upper bound that feeds into the right-hand side, write:
\[ (b-a)E\left[U_N\right] \leq E\left[(C \cdot Y)_N\right]. \]But we want an upper bound in terms of \(E\left[Y_N^-\right]\). Since \(Y = X - a\), we have \(Y^- = (X - a)^-\). Now, using pathwise bounds: during completed upcrossings, \(C \cdot Y\) gains at least \((b-a)\) each; during a possibly incomplete upcrossing, \(C \cdot Y\) gains at least \(Y_N - 0 = Y_N\) (since the upcrossing started from a value \(\leq 0\)); and the non-upcrossing contribution satisfies \(((1-C)\cdot Y)_N \leq 0\) when the process at time \(N\) is in a waiting phase below 0. The correct final bound is:
\[ (b-a)U_N \leq (C \cdot Y)_N \leq (C \cdot Y)_N + ((1-C)\cdot Y)_N^+ = Y_N - Y_0 + ((1-C)\cdot Y)_N^+ - ((1-C)\cdot Y)_N. \]The cleanest standard proof proceeds as follows. Define \(Z_n = (Y_n)^- = (X_n - a)^-\). Since \(x \mapsto x^-\) is convex and decreasing, \(Z_n = (X_n - a)^-\) is a submartingale when \(X\) is a supermartingale. The upcrossings of \(\left[0, b-a\right]\) by \(Y\) correspond to upcrossings of \(\left[a,b\right]\) by \(X\), and one checks pathwise that \((b-a)U_N \leq (C \cdot Y)_N \leq Y_N^-\). Taking expectations gives the result. \(\blacksquare\)
The upcrossing inequality is remarkable for its economy: it bounds oscillation (a path property) using only the first moment of the negative part. As we will see next, it is the engine behind all martingale convergence theorems.
2.3 Optional Sampling Theorems
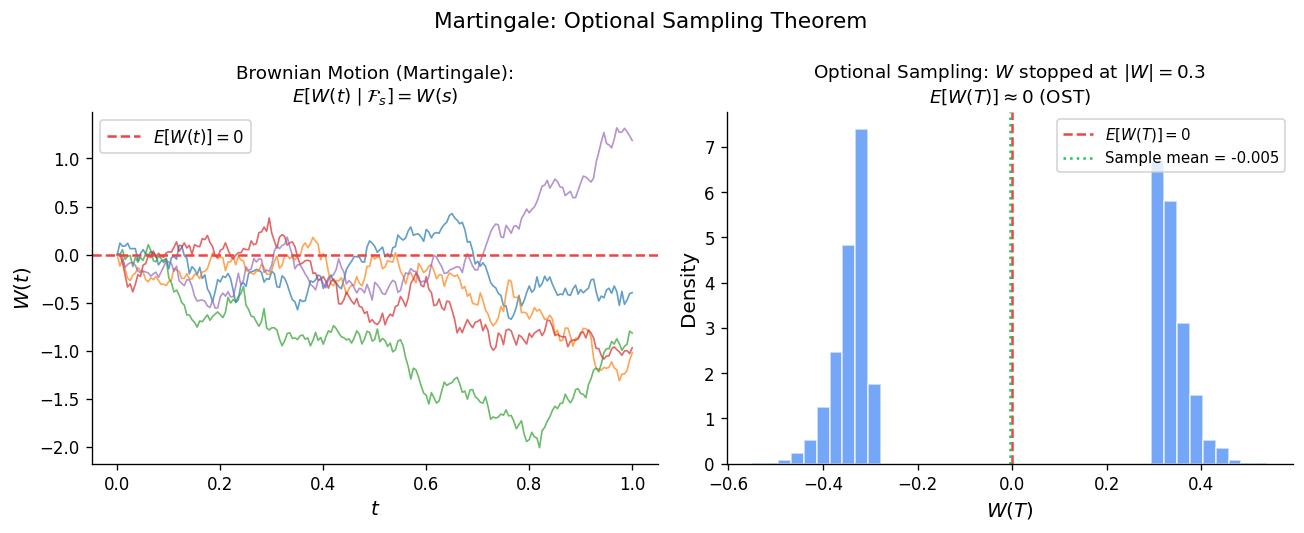
The optional sampling (or optional stopping) theorems describe when the martingale property is preserved at stopping times. The basic question is: if \(X\) is a martingale and \(S \leq T\) are stopping times, does \(E(X_T \mid \mathcal{F}_S) = X_S\) still hold? The answer depends on the integrability and closure properties of \(X\), and getting the hypotheses right is one of the subtleties of the subject.
We begin with convergence in \(L^2\), which provides a useful warmup.
Proposition 2.10 (L\(^2\) Convergence). If \(\{M_n\}_{n \geq 0}\) is a martingale with \(\sup_n E\left[M_n^2\right] < \infty\), then \(M_n\) converges in \(L^2\) and a.s. to a random variable \(M_\infty\) with \(E\left[M_\infty^2\right] < \infty\).
Proof. The key fact is that martingale increments are orthogonal in \(L^2\). For \(m < n\):
\[ E\left[(M_n - M_m)(M_m - M_k)\right] = E\left[E\left[(M_n - M_m)(M_m - M_k) \mid \mathcal{F}_m\right]\right] = E\left[(M_m - M_k) \cdot E(M_n - M_m \mid \mathcal{F}_m)\right] = 0, \]since \(E(M_n \mid \mathcal{F}_m) = M_m\). Therefore
\[ E\left[M_n^2\right] = E\left[M_0^2\right] + \sum_{k=1}^n E\left[(M_k - M_{k-1})^2\right]. \]The hypothesis \(\sup_n E\left[M_n^2\right] < \infty\) implies \(\sum_{k=1}^\infty E\left[(M_k - M_{k-1})^2\right] < \infty\), so the partial sums \(M_n = M_0 + \sum_{k=1}^n (M_k - M_{k-1})\) form a Cauchy sequence in \(L^2\). By completeness, \(M_n \to M_\infty\) in \(L^2\). Almost sure convergence follows either from the upcrossing inequality or from the \(L^2\) convergence combined with a subsequence argument. \(\blacksquare\)
The orthogonality of increments is a characteristically martingale phenomenon. It is the reason that the \(L^2\) theory of martingales is especially clean and connects naturally to Hilbert space methods. Submartingales and supermartingales do not enjoy this orthogonality.
Next, we state the optional sampling theorem for bounded stopping times — the simplest and most widely used version.
Theorem 2.11 (Optional Sampling — Bounded Stopping Times). Let \(\{X_n\}_{n \geq 0}\) be a supermartingale and let \(S \leq T\) be stopping times bounded by a constant \(N\) (i.e., \(T(\omega) \leq N\) for all \(\omega\)). Then
\[ E(X_T \mid \mathcal{F}_S) \leq X_S \quad \text{a.s.} \]If \(X\) is a martingale, equality holds.
Proof. We must show that for every \(A \in \mathcal{F}_S\), \(E(X_T \mathbf{1}_A) \leq E(X_S \mathbf{1}_A)\). Decompose:
\[ E(X_T \mathbf{1}_A) - E(X_S \mathbf{1}_A) = E\left[(X_T - X_S) \mathbf{1}_A\right] = \sum_{k=0}^{N-1} E\left[(X_{k+1} - X_k) \mathbf{1}_A \mathbf{1}_{\{S \leq k\}} \mathbf{1}_{\{T \geq k+1\}}\right]. \]This decomposition works because on the event \(\{S \leq k < T\}\), the increment \(X_{k+1} - X_k\) contributes to the difference \(X_T - X_S\). The indicator \(\mathbf{1}_A \mathbf{1}_{\{S \leq k\}} \mathbf{1}_{\{T \geq k+1\}}\) is \(\mathcal{F}_k\)-measurable: \(A \in \mathcal{F}_S\) and \(\{S \leq k\} \in \mathcal{F}_k\) give \(A \cap \{S \leq k\} \in \mathcal{F}_k\); similarly \(\{T \geq k+1\} = \{T \leq k\}^c \in \mathcal{F}_k\). Therefore
\[ E\left[(X_{k+1} - X_k) \mathbf{1}_A \mathbf{1}_{\{S \leq k\}} \mathbf{1}_{\{T \geq k+1\}}\right] = E\left[\mathbf{1}_A \mathbf{1}_{\{S \leq k\}} \mathbf{1}_{\{T \geq k+1\}} \, E(X_{k+1} - X_k \mid \mathcal{F}_k)\right] \leq 0, \]since \(E(X_{k+1} \mid \mathcal{F}_k) \leq X_k\) and the indicators are non-negative. Summing over \(k\) gives \(E(X_T \mathbf{1}_A) \leq E(X_S \mathbf{1}_A)\). \(\blacksquare\)
The boundedness assumption is essential: without it, the optional sampling theorem can fail even for uniformly integrable martingales with unbounded stopping times if one is not careful. The key to extending beyond bounded stopping times is the concept of a closed supermartingale.
Definition 2.12 (Closed Supermartingale). A supermartingale \(\{X_n\}_{n \geq 0}\) is closed (or closed on the right) if there exists an integrable random variable \(X_\infty\) such that
\[ X_n \geq E(X_\infty \mid \mathcal{F}_n) \quad \text{a.s. for all } n \geq 0. \]A martingale \(\{M_n\}\) is closed by \(M_\infty\) if \(M_n = E(M_\infty \mid \mathcal{F}_n)\) for all \(n\).
Closedness is the correct integrability condition that allows optional sampling at arbitrary (possibly unbounded) stopping times. A martingale that is closed by some \(L^1\) random variable is automatically uniformly integrable, as we shall see in the convergence section.
We first handle non-negative supermartingales, where the closing variable can be taken to be zero.
Theorem 2.13 (Optional Sampling — Non-Negative Supermartingales). Let \(\{X_n\}_{n \geq 0}\) be a non-negative supermartingale and let \(S \leq T\) be stopping times (not necessarily bounded). Then
\[ E(X_T \mid \mathcal{F}_S) \leq X_S \quad \text{a.s.,} \]where \(X_\infty := \lim_{n \to \infty} X_n\) (which exists a.s. by the supermartingale convergence theorem, Theorem 2.18 below), and \(X_T\) is defined as \(X_\infty\) on \(\{T = \infty\}\).
Proof. For each \(N\), the stopping times \(S \wedge N \leq T \wedge N\) are bounded by \(N\), so Theorem 2.11 gives \(E(X_{T \wedge N} \mid \mathcal{F}_{S \wedge N}) \leq X_{S \wedge N}\). Letting \(N \to \infty\), we need to pass the limit through the conditional expectation. By Fatou’s lemma for conditional expectations:
\[ E(X_T \mid \mathcal{F}_S) = E\left(\liminf_{N \to \infty} X_{T \wedge N} \mid \mathcal{F}_S\right) \leq \liminf_{N \to \infty} E(X_{T \wedge N} \mid \mathcal{F}_S). \]We use the fact that for \(\mathcal{F}_S \subseteq \mathcal{F}_{S \wedge N}\), and \(X_{S \wedge N} \to X_S\) a.s. The tower property and the bound from Theorem 2.11 give
\[ E(X_{T \wedge N} \mathbf{1}_A) \leq E(X_{S \wedge N} \mathbf{1}_A) \]for every \(A \in \mathcal{F}_S\). Taking \(N \to \infty\), the right-hand side converges to \(E(X_S \mathbf{1}_A)\) by dominated convergence (since \(X_{S \wedge N} \leq X_S\) when the process is a supermartingale… more precisely, we use Fatou on the left and monotone convergence or dominated convergence on the right). Since non-negative supermartingales are closed by \(X_\infty = 0\), Fatou’s lemma gives the result. \(\blacksquare\)
For general closed supermartingales, we need to decompose them into a martingale part and a non-negative part.
Lemma 2.14. If the martingale \(\{M_n\}\) is closed by \(M_\infty\) (i.e., \(M_n = E(M_\infty \mid \mathcal{F}_n)\)), then for any stopping time \(T\),
\[ M_T = E(M_\infty \mid \mathcal{F}_T). \]Proof. We must show that for each \(A \in \mathcal{F}_T\), \(E(M_T \mathbf{1}_A) = E(M_\infty \mathbf{1}_A)\). By the definition of \(\mathcal{F}_T\), \(A \cap \{T = n\} \in \mathcal{F}_n\) for each \(n\). Therefore
\[ E(M_T \mathbf{1}_A) = \sum_{n=0}^\infty E(M_n \mathbf{1}_{A \cap \{T=n\}}) = \sum_{n=0}^\infty E(E(M_\infty \mid \mathcal{F}_n) \mathbf{1}_{A \cap \{T=n\}}) = \sum_{n=0}^\infty E(M_\infty \mathbf{1}_{A \cap \{T=n\}}) = E(M_\infty \mathbf{1}_A), \]where the third equality uses the defining property of conditional expectation, since \(A \cap \{T = n\} \in \mathcal{F}_n\). \(\blacksquare\)
This lemma is surprisingly powerful: it says that a martingale closed by \(M_\infty\) can be sampled at any stopping time (no boundedness required) and still gives the conditional expectation of \(M_\infty\).
Theorem 2.15 (Optional Sampling — Closed Supermartingales). Let \(\{X_n\}_{n \geq 0}\) be a supermartingale closed by \(X_\infty\), and let \(S \leq T\) be stopping times. Then
\[ E(X_T \mid \mathcal{F}_S) \leq X_S \quad \text{a.s.} \]Proof. By the Doob decomposition, write \(X_n = M_n - A_n\) where \(M_n\) is a martingale and \(A_n\) is a non-negative non-decreasing previsible process with \(A_0 = 0\). The martingale \(M_n\) is closed by \(M_\infty = X_\infty + A_\infty\) (where \(A_\infty = \lim A_n\) exists since \(A_n\) is non-decreasing and bounded in \(L^1\)). The process \(A_n\) is a non-negative submartingale (in fact, non-decreasing), so \(-A_n\) is a non-negative supermartingale up to a sign — more precisely, \(A\) is non-decreasing so \(A_T \geq A_S\).
For \(A \in \mathcal{F}_S\):
\[ E(X_T \mathbf{1}_A) = E(M_T \mathbf{1}_A) - E(A_T \mathbf{1}_A). \]By Lemma 2.14, \(E(M_T \mathbf{1}_A) = E(M_\infty \mathbf{1}_A) = E(M_S \mathbf{1}_A)\) (applying the lemma to both \(T\) and \(S\)). Since \(A_T \geq A_S\) a.s. (the process is non-decreasing):
\[ E(X_T \mathbf{1}_A) = E(M_S \mathbf{1}_A) - E(A_T \mathbf{1}_A) \leq E(M_S \mathbf{1}_A) - E(A_S \mathbf{1}_A) = E(X_S \mathbf{1}_A). \]This gives \(E(X_T \mid \mathcal{F}_S) \leq X_S\). \(\blacksquare\)
There is also a version for negatively indexed supermartingales (indexed by \(\mathbb{Z}_{\leq 0}\) or more generally by a directed set going backward), which arises in certain limit arguments. The key fact is:
Proposition 2.16 (Negatively Indexed Supermartingales). If \(\{X_n\}_{n \leq 0}\) is a supermartingale with \(\sup_{n \leq 0} E\left[X_n^+\right] < \infty\), then \(\{X_n\}\) is uniformly integrable and \(X_n\) converges in \(L^1\) and a.s. as \(n \to -\infty\).
The condition \(\sup E\left[X_n^+\right] < \infty\) is equivalent to \(\sup E\left[|X_n|\right] < \infty\) for supermartingales (since \(E\left[X_n^-\right] \leq E\left[X_n^+\right] - E\left[X_0\right]\) by the supermartingale inequality iterated). This uniform \(L^1\) bound is then bootstrapped to uniform integrability using the upcrossing-style argument.
We now pass to continuous time. The challenge is that continuous-time processes have uncountably many time points, so one cannot simply “sum over \(n\)” as in discrete time. The right-continuity assumption and dyadic approximation overcome this obstacle.
Theorem 2.17 (Optional Sampling — Continuous Time). Let \(\{X_t\}_{t \geq 0}\) be a right-continuous supermartingale closed by an integrable random variable \(X_\infty\) (i.e., \(X_t \geq E(X_\infty \mid \mathcal{F}_t)\) for all \(t \geq 0\)). Let \(S \leq T\) be stopping times. Then
\[ E(X_T \mid \mathcal{F}_S) \leq X_S \quad \text{a.s.} \]If \(X\) is a martingale closed by \(X_\infty\), equality holds.
Proof. The idea is to approximate the continuous-time stopping times by discrete ones and apply the discrete result. Define the dyadic approximations
\[ T_n = 2^{-n}(\lfloor 2^n T \rfloor + 1), \]and similarly \(S_n = 2^{-n}(\lfloor 2^n S \rfloor + 1)\). Then \(T_n\) takes values in \(\{k 2^{-n} : k \geq 1\}\), \(T_n \geq T\), and \(T_n \downarrow T\) as \(n \to \infty\).
Each \(T_n\) is a stopping time: \(\{T_n \leq t\} = \{T < t\} \cap \{\text{appropriate dyadic condition}\} \in \mathcal{F}_t\) by right-continuity of the filtration. Similarly \(S_n\) is a stopping time with \(S_n \geq S\) and \(S_n \downarrow S\).
For fixed \(n\), restrict \(X\) to the discrete times \(\{k 2^{-n} : k \geq 0\}\). At these times, \(X\) is still a supermartingale (by the continuous-time supermartingale property applied to \(s = k2^{-n}\), \(t = (k+1)2^{-n}\)). The stopping times \(S_n \leq T_n\) take values in this discrete set. By the discrete optional sampling theorem for closed supermartingales (Theorem 2.15):
\[ E(X_{T_n} \mid \mathcal{F}_{S_n}) \leq X_{S_n}. \]As \(n \to \infty\), \(T_n \downarrow T\) and \(S_n \downarrow S\). By right-continuity of paths, \(X_{T_n} \to X_T\) and \(X_{S_n} \to X_S\) a.s. The closure condition provides the uniform integrability needed (via dominated convergence or conditional Fatou) to pass to the limit:
\[ E(X_T \mid \mathcal{F}_S) \leq X_S. \quad \blacksquare \]The dyadic approximation technique is fundamental in continuous-time probability. Whenever a discrete-time result needs to be lifted to continuous time, one typically constructs dyadic stopping times that decrease to the true stopping time, applies the discrete result, and passes to the limit using right-continuity and an integrability condition.
Several important corollaries follow immediately.
Corollary 2.17.1. If \(\{M_t\}\) is a right-continuous martingale closed by \(M_\infty\), and \(S \leq T\) are stopping times, then \(E(M_T \mid \mathcal{F}_S) = M_S\) a.s.
Corollary 2.17.2. If \(\{X_t\}\) is a right-continuous supermartingale and \(T\) is a bounded stopping time (\(T \leq c\) a.s.), then \(E(X_T) \leq E(X_0)\).
Corollary 2.17.3 (Characterization of Martingales). A right-continuous adapted integrable process \(\{M_t\}\) is a martingale if and only if \(E(M_T) = E(M_0)\) for every bounded stopping time \(T\).
This last corollary is especially useful: to verify the martingale property, it suffices to check that stopping does not change the expected value. This is often easier than directly verifying the conditional expectation condition at every pair of deterministic times.
2.4 Martingale Convergence
The convergence theory for martingales and supermartingales is one of the deepest parts of classical probability. The upcrossing inequality, developed in Section 2.2, is the key tool.
Theorem 2.18 (Supermartingale Convergence Theorem). Let \(\{X_t\}_{t \geq 0}\) be a right-continuous supermartingale (in continuous time) or \(\{X_n\}_{n \geq 0}\) (in discrete time). If
\[ \sup_{t \geq 0} E\left[X_t^-\right] < \infty, \]then \(\lim_{t \to \infty} X_t\) exists and is finite almost surely.
Proof. We give the proof in discrete time; the continuous-time version follows by restricting to rational times and using right-continuity.
If \(\liminf X_n < \limsup X_n\) on a set of positive measure, there exist rationals \(a < b\) such that the event \(\{\liminf X_n < a < b < \limsup X_n\}\) has positive probability. On this event, \(X\) crosses the interval \(\left[a, b\right]\) infinitely many times, so \(U_N^X(\left[a, b\right]) \to \infty\) as \(N \to \infty\).
By Doob’s upcrossing inequality (Theorem 2.9):
\[ (b - a) \, E\left[U_N^X(\left[a, b\right])\right] \leq E\left[(X_N - a)^-\right] \leq E\left[X_N^-\right] + |a|. \]The hypothesis \(\sup_N E\left[X_N^-\right] < \infty\) gives a uniform bound on the right-hand side. By the monotone convergence theorem, \(E\left[U_\infty^X(\left[a,b\right])\right] < \infty\), so \(U_\infty^X(\left[a,b\right]) < \infty\) a.s. This means the event \(\{\liminf X_n < a < b < \limsup X_n\}\) has probability zero. Taking the union over all rational pairs \(a < b\) (a countable union of null sets), we conclude \(\liminf X_n = \limsup X_n\) a.s., i.e., the limit exists a.s.
Finiteness of the limit follows from \(E\left[X_0\right] \geq E\left[X_n\right] = E\left[X_n^+\right] - E\left[X_n^-\right]\), so \(E\left[X_n^+\right] \leq E\left[X_0\right] + \sup E\left[X_n^-\right] < \infty\). Hence \(\sup E\left[|X_n|\right] < \infty\), and in particular \(|X_n|\) cannot diverge to \(+\infty\) on a set of positive measure (by Fatou’s lemma). \(\blacksquare\)
A particularly clean special case deserves its own statement.
Corollary 2.19. Every non-negative supermartingale converges almost surely.
This is immediate since \(X_t \geq 0\) implies \(X_t^- = 0\), so the condition \(\sup E\left[X_t^-\right] < \infty\) is trivially satisfied. Non-negative supermartingales are the workhorses of probability: exponential martingales, likelihood ratios, and many test supermartingales fall into this category.
The convergence theorem guarantees almost sure convergence, but says nothing about \(L^1\) convergence. The gap between a.s. convergence and \(L^1\) convergence for martingales is filled by the following equivalences.
Theorem 2.20 (Characterization of \(L^1\) Convergence for Martingales). For a martingale \(\{M_n\}_{n \geq 0}\), the following are equivalent:
(i) \(M_n \to M_\infty\) in \(L^1\),
(ii) \(\{M_n\}\) is closed (i.e., there exists an integrable \(Y\) with \(M_n = E(Y \mid \mathcal{F}_n)\)),
(iii) \(\{M_n\}\) is uniformly integrable,
(iv) \(\{M_n\}\) converges a.s. and in \(L^1\), and \(M_n = E(M_\infty \mid \mathcal{F}_n)\) for all \(n\).
The equivalence (ii) \(\Leftrightarrow\) (iii) is the most important: uniform integrability is the “right” condition for \(L^1\) martingale convergence, and it is equivalent to being closed. Direction (ii) \(\Rightarrow\) (iii) follows because conditional expectations of a single integrable random variable form a uniformly integrable family (a standard result in measure theory). Direction (iii) \(\Rightarrow\) (i) uses the Vitali convergence theorem: uniform integrability plus a.s. convergence (which we already have from Theorem 2.18) implies \(L^1\) convergence. Direction (i) \(\Rightarrow\) (iv) is then obtained by taking limits in the relation \(E(M_n \mathbf{1}_A) = E(M_m \mathbf{1}_A)\) for \(A \in \mathcal{F}_m\) and \(n \geq m\).
The practical takeaway is that for a uniformly integrable martingale, optional sampling holds at arbitrary stopping times:
Corollary 2.21 (UI Martingale Optional Sampling). If \(\{M_n\}\) is a uniformly integrable martingale with limit \(M_\infty\), then for any stopping times \(S \leq T\) (possibly taking the value \(+\infty\)):
\[ E(M_T \mid \mathcal{F}_S) = M_S \quad \text{a.s.} \]This is the definitive version of optional sampling for discrete-time martingales. It applies to unbounded stopping times, requires no moment conditions beyond uniform integrability, and gives equality (not just an inequality).
2.5 Brownian Motion
Brownian motion is the most fundamental continuous-time stochastic process and the prototype for all of stochastic calculus. It arises as the scaling limit of random walks, as the canonical Gaussian process with independent increments, and as the unique continuous martingale with a prescribed quadratic variation. In this section, we establish its basic properties and the key structural results that will be needed for stochastic integration.
![Standard Brownian motion: 5 sample paths on [0,1]](/pics/stat902/brownian_motion.png)
Definition 2.22 (Standard Brownian Motion). A stochastic process \(\{B_t\}_{t \geq 0}\) on a probability space \((\Omega, \mathcal{F}, P)\) is a standard (one-dimensional) Brownian motion if:
(i) \(B_0 = 0\) a.s.,
(ii) \(t \mapsto B_t(\omega)\) is continuous for a.s. every \(\omega\),
(iii) for any \(0 \leq t_1 < t_2 < \cdots < t_n\), the increments \(B_{t_2} - B_{t_1}, B_{t_3} - B_{t_2}, \ldots, B_{t_n} - B_{t_{n-1}}\) are independent,
(iv) for any \(s < t\), \(B_t - B_s \sim \mathcal{N}(0, t - s)\).
Conditions (iii) and (iv) together say that Brownian motion has stationary independent Gaussian increments. Stationarity means the distribution of \(B_t - B_s\) depends only on \(t - s\), not on the individual values of \(s\) and \(t\).
There is an equivalent characterization that is often more convenient for theoretical purposes.
Proposition 2.23 (Gaussian Process Characterization). A stochastic process \(\{B_t\}_{t \geq 0}\) with continuous paths and \(B_0 = 0\) is a standard Brownian motion if and only if it is a centered Gaussian process with covariance function
\[ E(B_s B_t) = s \wedge t := \min(s, t). \]Proof. (\(\Rightarrow\)) Suppose \(B\) is a standard Brownian motion. Then \(E\left[B_t\right] = 0\) for all \(t\) (since \(B_t = B_t - B_0 \sim \mathcal{N}(0, t)\)). For the covariance, assume \(s \leq t\):
\[ E(B_s B_t) = E\left[B_s(B_s + (B_t - B_s))\right] = E\left[B_s^2\right] + E\left[B_s(B_t - B_s)\right]. \]The second term vanishes by independence of \(B_s = B_s - B_0\) and \(B_t - B_s\) (using that these are increments over disjoint intervals; strictly speaking, \(B_s\) is measurable with respect to \(\sigma(B_u : u \leq s)\) and \(B_t - B_s\) is independent of this \(\sigma\)-algebra). So \(E(B_s B_t) = E\left[B_s^2\right] = s = s \wedge t\). Any finite-dimensional vector \((B_{t_1}, \ldots, B_{t_n})\) is a linear function of the independent Gaussian increments, hence jointly Gaussian.
(\(\Leftarrow\)) Suppose \(B\) is a centered Gaussian process with \(E(B_s B_t) = s \wedge t\). For any \(s < t\), the increment \(B_t - B_s\) is Gaussian (as a linear combination of jointly Gaussian variables) with mean zero and variance
\[ \text{Var}(B_t - B_s) = E\left[B_t^2\right] - 2E\left[B_s B_t\right] + E\left[B_s^2\right] = t - 2s + s = t - s. \]For independence of increments over disjoint intervals: if \(a < b \leq c < d\), then
\[ \text{Cov}(B_b - B_a, B_d - B_c) = E(B_b B_d) - E(B_b B_c) - E(B_a B_d) + E(B_a B_c) = b - b - a + a = 0. \]Since uncorrelated jointly Gaussian random variables are independent, the increments are independent. \(\blacksquare\)
The Gaussian process viewpoint is powerful because it characterizes Brownian motion entirely through its first two moments. Any process with continuous paths, zero mean, and covariance \(s \wedge t\) is automatically Brownian motion — there is no need to check the increment structure directly.
The next result is one of the most important characterizations in stochastic calculus.
Theorem 2.24 (Lévy’s Characterization of Brownian Motion). Let \(\{X_t\}_{t \geq 0}\) be a continuous adapted process with \(X_0 = 0\) on a filtered probability space satisfying the usual conditions. Then \(X\) is a standard Brownian motion if and only if both \(X_t\) and \(X_t^2 - t\) are martingales with respect to \(\{\mathcal{F}_t\}\).
Lévy’s characterization is remarkable because it replaces the conditions of independent Gaussian increments with a martingale condition. The condition that \(X_t\) is a martingale encodes the “fair game” property (zero drift). The condition that \(X_t^2 - t\) is a martingale encodes the correct variance growth rate: \(E(X_t^2 \mid \mathcal{F}_s) = X_s^2 + (t - s)\), which says the conditional variance of \(X_t - X_s\) given \(\mathcal{F}_s\) is \(t - s\). For a continuous martingale, these two conditions together force the increments to be Gaussian (by a central limit theorem argument applied to the martingale representation). This characterization is the basis for many constructions in stochastic calculus, where one builds a process, verifies the two martingale conditions, and concludes it must be Brownian motion.
Theorem 2.25 (Strong Markov Property). Let \(\{B_t\}\) be a standard Brownian motion and \(T\) a finite stopping time. Then the process \(\{\tilde{B}_t\}_{t \geq 0}\) defined by \(\tilde{B}_t = B_{T+t} - B_T\) is a standard Brownian motion independent of \(\mathcal{F}_T\).
The strong Markov property says that Brownian motion “restarts” at any stopping time, not just at deterministic times (which would be the ordinary Markov property). This is essential for analyzing hitting times and excursions. The proof uses the fact that \(B\) has independent increments and the approximation of \(T\) by dyadic stopping times \(T_n \downarrow T\).
Brownian motion has a rich collection of symmetries that generate new Brownian motions from old ones.
Proposition 2.26 (Scaling Property). If \(\{B_t\}_{t \geq 0}\) is a standard Brownian motion and \(a > 0\), then the process \(\{a^{-1/2} B_{at}\}_{t \geq 0}\) is also a standard Brownian motion.
This follows immediately from the Gaussian process characterization: \(a^{-1/2} B_{at}\) has continuous paths, starts at zero, is centered Gaussian, and has covariance \(a^{-1} E(B_{as} B_{at}) = a^{-1}(as \wedge at) = s \wedge t\). The scaling property expresses the self-similarity of Brownian motion: zooming in or out on the path produces a statistically identical process (after appropriate rescaling of time and space).
Proposition 2.27 (Time Inversion). Define \(X_0 = 0\) and \(X_t = t B(1/t)\) for \(t > 0\). Then \(\{X_t\}_{t \geq 0}\) is a standard Brownian motion.
Proof. The process \(X\) is centered Gaussian (as a linear function of \(B\)). Its covariance for \(0 < s \leq t\) is
\[ E(X_s X_t) = st \, E\left(B(1/s) B(1/t)\right) = st \cdot (1/t) = s = s \wedge t, \]since \(1/s \geq 1/t\) when \(s \leq t\), so \(1/s \wedge 1/t = 1/t\). Continuity at \(t = 0\) requires checking that \(X_t = tB(1/t) \to 0\) a.s. as \(t \to 0^+\). This follows from the law of the iterated logarithm: \(|B(u)| = O(\sqrt{u \log \log u})\) as \(u \to \infty\), so \(|tB(1/t)| = O(\sqrt{t \log \log(1/t)}) \to 0\). By the Gaussian process characterization, \(X\) is a Brownian motion. \(\blacksquare\)
Time inversion relates the behavior of Brownian motion near zero to its behavior near infinity, and vice versa. For instance, the fact that \(B_t / t \to 0\) a.s. as \(t \to \infty\) (law of large numbers) is equivalent, via time inversion, to the continuity of paths at zero.
An elegant consequence of the strong Markov property concerns the zeros of Brownian motion.
Proposition 2.28 (Zero is an Accumulation Point of Zeros). Almost surely, for every \(\epsilon > 0\), there exists \(t \in (0, \epsilon)\) with \(B_t = 0\). That is, 0 is an accumulation point of the zero set \(\{t \geq 0 : B_t = 0\}\).
This follows from the time inversion and the recurrence of one-dimensional Brownian motion. The zero set of Brownian motion is, in fact, a closed set with no isolated points — a perfect set — which is uncountable yet has Lebesgue measure zero. This is one of the first hints that Brownian paths are far more irregular than any smooth function.
The reflection principle connects the maximum of Brownian motion to its endpoint distribution.
Theorem 2.29 (Reflection Principle). Let \(\{B_t\}\) be a standard Brownian motion and define \(M_t = \sup_{s \leq t} B_s\). Then for \(a > 0\):
\[ P(M_t \geq a) = 2 P(B_t \geq a). \]Proof. Let \(T_a = \inf\{s \geq 0 : B_s = a\}\) be the first hitting time of level \(a\). Then \(\{M_t \geq a\} = \{T_a \leq t\}\). By the strong Markov property, the process \(\tilde{B}_s = B_{T_a + s} - B_{T_a}\) is a Brownian motion independent of \(\mathcal{F}_{T_a}\), started at 0. By symmetry of Brownian motion, \(\tilde{B}_{t - T_a}\) has the same distribution as \(-\tilde{B}_{t - T_a}\) (conditional on \(T_a \leq t\)). Therefore
\[ P(B_t \geq a \mid T_a \leq t) = P(B_t \leq a \mid T_a \leq t), \]since on \(\{T_a \leq t\}\), \(B_t = a + \tilde{B}_{t - T_a}\) and \(\tilde{B}_{t-T_a}\) is symmetric about 0. Now
\[ P(M_t \geq a) = P(T_a \leq t) = P(B_t \geq a \mid T_a \leq t) \cdot P(T_a \leq t) + P(B_t < a \mid T_a \leq t) \cdot P(T_a \leq t). \]Wait — more carefully:
\[ P(B_t \geq a) = P(B_t \geq a, T_a \leq t) = P(B_t \geq a \mid T_a \leq t) P(T_a \leq t), \]where the first equality uses \(\{B_t \geq a\} \subseteq \{T_a \leq t\}\) (by continuity, to reach above \(a\) the process must first hit \(a\)). By the symmetry argument, \(P(B_t \geq a \mid T_a \leq t) = 1/2\). Therefore
\[ P(B_t \geq a) = \frac{1}{2} P(T_a \leq t) = \frac{1}{2} P(M_t \geq a), \]which gives \(P(M_t \geq a) = 2P(B_t \geq a)\). \(\blacksquare\)
The reflection principle is so named because the proof “reflects” the Brownian path after the hitting time \(T_a\): the reflected path \(2a - B_t\) for \(t \geq T_a\) has the same distribution as the original. The formula \(P(M_t \geq a) = 2P(B_t \geq a)\) can be written explicitly using the Gaussian tail: \(P(M_t \geq a) = 2\left(1 - \Phi(a / \sqrt{t})\right)\), where \(\Phi\) is the standard normal CDF. This shows that the running maximum of Brownian motion has a half-normal distribution.
We conclude this chapter with a fundamental regularity result: Brownian motion has paths of unbounded variation.
Theorem 2.30 (Brownian Motion Has Unbounded Variation). Almost surely, Brownian motion has infinite (first) variation on every interval \(\left[a, b\right]\) with \(a < b\). More precisely, the quadratic variation of \(B\) on \(\left[a, b\right]\) equals \(b - a\): if \(\Pi_n = \{a = t_0^n < t_1^n < \cdots < t_{k_n}^n = b\}\) is a sequence of partitions with mesh \(|\Pi_n| \to 0\), then
\[ \sum_{i=0}^{k_n - 1} (B_{t_{i+1}^n} - B_{t_i^n})^2 \to b - a \quad \text{in } L^2 \text{ (and hence in probability)}. \]Proof. Define \(Q_n = \sum_{i=0}^{k_n - 1} (B_{t_{i+1}^n} - B_{t_i^n})^2\). Set \(\Delta_i = B_{t_{i+1}^n} - B_{t_i^n}\) and \(\delta_i = t_{i+1}^n - t_i^n\). Each \(\Delta_i \sim \mathcal{N}(0, \delta_i)\) and the increments are independent.
First, compute the mean:
\[ E\left[Q_n\right] = \sum_{i=0}^{k_n - 1} E\left[\Delta_i^2\right] = \sum_{i=0}^{k_n - 1} \delta_i = b - a. \]Next, compute the variance. Since the increments are independent:
\[ \text{Var}(Q_n) = \sum_{i=0}^{k_n - 1} \text{Var}(\Delta_i^2). \]For \(Z \sim \mathcal{N}(0, \sigma^2)\), we have \(E\left[Z^4\right] = 3\sigma^4\), so \(\text{Var}(Z^2) = 3\sigma^4 - \sigma^4 = 2\sigma^4\). Thus
\[ \text{Var}(Q_n) = \sum_{i=0}^{k_n - 1} 2\delta_i^2 \leq 2 |\Pi_n| \sum_{i=0}^{k_n - 1} \delta_i = 2 |\Pi_n| (b - a) \to 0 \]as \(|\Pi_n| \to 0\). Therefore \(Q_n \to b - a\) in \(L^2\).
To conclude unbounded variation: if \(B\) had finite first variation \(V\) on \(\left[a, b\right]\), then
\[ Q_n = \sum_i |\Delta_i|^2 \leq \max_i |\Delta_i| \cdot \sum_i |\Delta_i| \leq \max_i |\Delta_i| \cdot V. \]By uniform continuity of Brownian paths on \(\left[a, b\right]\), \(\max_i |\Delta_i| \to 0\) as \(|\Pi_n| \to 0\). This would force \(Q_n \to 0\), contradicting \(Q_n \to b - a > 0\). Hence the first variation is infinite a.s. \(\blacksquare\)
The fact that Brownian paths have infinite variation but finite quadratic variation is the fundamental reason that stochastic calculus differs from ordinary calculus. In the Riemann–Stieltjes theory, one integrates against functions of bounded variation. Since Brownian motion fails this condition, a new theory of integration — the Ito integral — is required. The quadratic variation \(\left[B, B\right]_t = t\) will play the role of the “differential” \((dB)^2 = dt\) in Ito’s formula, which is the subject of the next chapter.
Chapter 3: Stochastic Integration
The centerpiece of stochastic calculus is the stochastic integral \(\int f \, dB\), which extends the classical theory of integration to allow integration against Brownian motion. The need for a new theory arises from a fundamental obstruction: Brownian motion has paths of unbounded variation on every interval, so the Lebesgue–Stieltjes integral \(\int f \, dB\) cannot be defined pathwise in the classical sense. Instead, we construct the Itô integral as an \(L^2\) limit, exploiting the isometric structure that connects stochastic integration to ordinary \(L^2\) theory. This chapter develops the construction, establishes the key properties of the integral, extends it to broader classes of integrands, and culminates in Itô’s formula — the chain rule of stochastic calculus.
3.1 Construction of the Itô Integral
The Obstruction
Fix an interval \([a, b]\) and a probability space \((\Omega, \mathcal{F}, P)\) equipped with a filtration \((\mathcal{F}_t)_{t \in [a,b]}\) and a standard Brownian motion \((B_t)_{t \in [a,b]}\). Our goal is to define the stochastic integral
\[ \int_a^b f(t, \omega) \, dB_t(\omega) \]for a suitable class of random processes \(f\). In classical analysis, if \(g\) is a function of bounded variation on \([a,b]\), then \(\int f \, dg\) is well-defined as a Lebesgue–Stieltjes integral. However, we showed in Chapter 2 that almost every path of Brownian motion has unbounded variation on every interval. Consequently, the Lebesgue–Stieltjes approach fails, and a fundamentally different construction is required.
The key insight, due to Itô, is to define the integral first for simple processes, establish an isometry that identifies the stochastic integral with an element of \(L^2\), and then extend by continuity to a larger class of integrands.
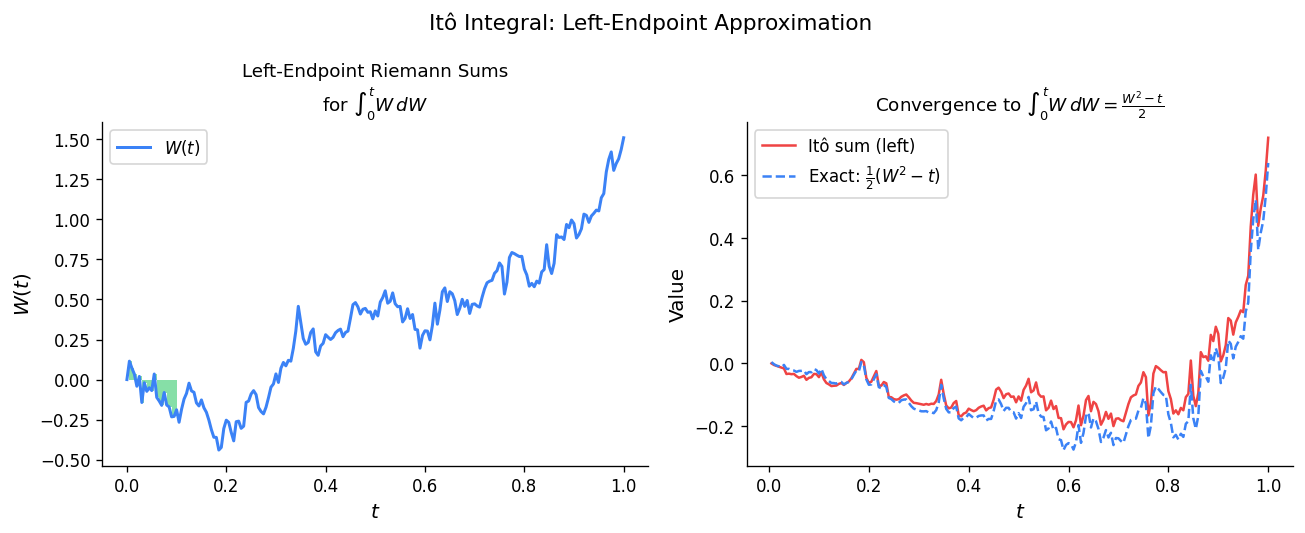
The Space of Integrands
We begin by specifying the natural domain for the Itô integral.
Definition 3.1.1 (The Space \(V_I\)). Let \(I = [a, b]\). Define \(V = V_I\) to be the collection of all processes \(f : [a, b] \times \Omega \to \mathbb{R}\) satisfying:
- \(f\) is \(\mathcal{B}([a,b]) \otimes \mathcal{F}\)-measurable (jointly measurable),
- \(f\) is \(\mathcal{F}_t\)-adapted: for each \(t \in [a, b]\), the map \(\omega \mapsto f(t, \omega)\) is \(\mathcal{F}_t\)-measurable,
- \(f\) satisfies the square-integrability condition: \[ \|f\|_V^2 := E\left(\int_a^b f(t, \omega)^2 \, dt\right) < \infty. \]
The space \(V\) is a Hilbert space under the inner product \(\langle f, g \rangle_V = E\left(\int_a^b f(t)g(t) \, dt\right)\). The joint measurability condition ensures that the integral \(\int_a^b f^2 \, dt\) is well-defined as a random variable, while adaptedness is essential for the martingale properties of the stochastic integral. The square-integrability condition provides the \(L^2\) structure needed for the extension argument.
Elementary Processes
The construction begins with a class of processes for which the stochastic integral has an obvious definition.
Definition 3.1.2 (Elementary Process). A process \(\varphi \in V\) is called elementary if there exists a partition \(a = t_0 < t_1 < \cdots < t_n = b\) and random variables \(A_0, A_1, \ldots, A_{n-1}\) such that:
- Each \(A_j\) is bounded and \(\mathcal{F}_{t_j}\)-measurable,
- \(\varphi(t, \omega) = \sum_{j=0}^{n-1} A_j(\omega) \, \mathbf{1}_{[t_j, t_{j+1})}(t)\).
For an elementary process, the stochastic integral is defined in the only natural way: each \(A_j\) is held constant over \([t_j, t_{j+1})\) and multiplied by the corresponding Brownian increment.
Definition 3.1.3 (Stochastic Integral of Elementary Processes). For an elementary process \(\varphi = \sum_{j=0}^{n-1} A_j \, \mathbf{1}_{[t_j, t_{j+1})}\), define
\[ \int_a^b \varphi \, dB := \sum_{j=0}^{n-1} A_j \left(B_{t_{j+1}} - B_{t_j}\right). \]Observe that each term \(A_j(B_{t_{j+1}} - B_{t_j})\) is well-defined: \(A_j\) is \(\mathcal{F}_{t_j}\)-measurable, and the increment \(B_{t_{j+1}} - B_{t_j}\) is independent of \(\mathcal{F}_{t_j}\). This independence is the engine that drives the entire theory.
The Itô Isometry for Elementary Processes
The following isometry is the cornerstone of the construction. It says that the \(L^2\)-norm of the stochastic integral equals the \(V\)-norm of the integrand.
Theorem 3.1.4 (Itô Isometry for Elementary Processes). Let \(\varphi = \sum_{j=0}^{n-1} A_j \, \mathbf{1}_{[t_j, t_{j+1})}\) be an elementary process. Then
\[ E\left[\left(\int_a^b \varphi \, dB\right)^2\right] = E\left(\int_a^b \varphi(t)^2 \, dt\right). \]Proof. We expand the left-hand side:
\[ E\left[\left(\sum_{j=0}^{n-1} A_j (B_{t_{j+1}} - B_{t_j})\right)^2\right] = \sum_{j=0}^{n-1} \sum_{k=0}^{n-1} E\left[A_j A_k (B_{t_{j+1}} - B_{t_j})(B_{t_{k+1}} - B_{t_k})\right]. \]We show that the cross terms vanish. Without loss of generality, suppose \(j < k\). Then \(t_j < t_{j+1} \leq t_k < t_{k+1}\), and the product \(A_j A_k (B_{t_{j+1}} - B_{t_j})\) is \(\mathcal{F}_{t_k}\)-measurable, while \(B_{t_{k+1}} - B_{t_k}\) is independent of \(\mathcal{F}_{t_k}\) and has mean zero. Therefore
\[ E\left[A_j A_k (B_{t_{j+1}} - B_{t_j})(B_{t_{k+1}} - B_{t_k})\right] = E\left[A_j A_k (B_{t_{j+1}} - B_{t_j})\right] \cdot E\left[B_{t_{k+1}} - B_{t_k}\right] = 0. \]Only the diagonal terms \(j = k\) survive. For each such term, \(A_j^2\) is \(\mathcal{F}_{t_j}\)-measurable and \((B_{t_{j+1}} - B_{t_j})^2\) is independent of \(\mathcal{F}_{t_j}\), so
\[ E\left[A_j^2 (B_{t_{j+1}} - B_{t_j})^2\right] = E\left[A_j^2\right] \cdot E\left[(B_{t_{j+1}} - B_{t_j})^2\right] = E\left[A_j^2\right] \cdot (t_{j+1} - t_j). \]Summing over \(j\):
\[ E\left[\left(\int_a^b \varphi \, dB\right)^2\right] = \sum_{j=0}^{n-1} E\left[A_j^2\right](t_{j+1} - t_j) = E\left(\sum_{j=0}^{n-1} A_j^2 (t_{j+1} - t_j)\right) = E\left(\int_a^b \varphi(t)^2 \, dt\right). \quad \blacksquare \]The Itô isometry has an immediate but powerful consequence: the map \(\varphi \mapsto \int \varphi \, dB\) is a linear isometry from the elementary processes (equipped with the \(V\)-norm) into \(L^2(\Omega, \mathcal{F}, P)\). If we can show that elementary processes are dense in \(V\), then this isometry extends uniquely to all of \(V\).
Approximation Lemmas
The density argument proceeds in three steps, progressively relaxing the conditions on the integrand.
Lemma 3.1.5 (Bounded Approximation). Let \(f \in V\). Define the truncation \(f_n(t, \omega) = f(t, \omega) \cdot \mathbf{1}_{\{|f(t,\omega)| \leq n\}}\). Then each \(f_n \in V\) is bounded, and \(\|f_n - f\|_V \to 0\).
Lemma 3.1.6 (Continuous Approximation). Let \(f \in V\) be bounded. Then there exists a sequence of bounded, continuous, adapted processes \((g_n)\) with \(\|g_n - f\|_V \to 0\).
Lemma 3.1.7 (Elementary Approximation). Let \(g \in V\) be bounded and continuous. Then there exist elementary processes \((\varphi_n)\) with \(\|\varphi_n - g\|_V \to 0\).
The proofs use, respectively, truncation and dominated convergence; backward mollification to preserve adaptedness; and piecewise-constant approximation on uniform partitions. Combining all three, elementary processes are dense in \(V\).
Extension to General Integrands
Theorem 3.1.8 (Existence and Uniqueness of the Itô Integral). There exists a unique linear isometry \(I : V \to L^2(\Omega, \mathcal{F}, P)\) such that \(I(\varphi) = \sum_j A_j(B_{t_{j+1}} - B_{t_j})\) for every elementary \(\varphi\). For general \(f \in V\), the Itô integral is
\[ \int_a^b f \, dB := I(f) = \lim_{n \to \infty} \int_a^b \varphi_n \, dB \quad \text{in } L^2, \]where \((\varphi_n)\) is any sequence of elementary processes with \(\|\varphi_n - f\|_V \to 0\). The Itô isometry holds:
\[ E\left[\left(\int_a^b f \, dB\right)^2\right] = E\left(\int_a^b f^2 \, dt\right). \]3.2 Properties of the Stochastic Integral
The stochastic integral is linear: for \(f, g \in V\) and constants \(\alpha, \beta\),
\[ \int_a^b (\alpha f + \beta g) \, dB = \alpha \int_a^b f \, dB + \beta \int_a^b g \, dB. \]Far more significant is the martingale property.
Doob’s Maximal Inequalities
Before stating the main result, we record the key maximal inequalities that will control the supremum of our martingale.
Theorem 3.2.1 (Doob’s Submartingale Inequality). Let \((M_n)_{n=0}^N\) be a submartingale. For \(\lambda > 0\),
\[ \lambda \, P\!\left(\max_{0 \leq n \leq N} M_n \geq \lambda\right) \leq E\!\left[\left|M_N\right| \, \mathbf{1}_{\{\max_n M_n \geq \lambda\}}\right]. \]Theorem 3.2.2 (Doob’s Martingale Inequality — Continuous Case). Let \((M_t)\) be a continuous martingale on \([0, T]\). For \(\lambda > 0\) and \(p \geq 1\),
\[ P\!\left(\sup_{0 \leq t \leq T} |M_t| \geq \lambda\right) \leq \frac{1}{\lambda^p} \, E\!\left[|M_T|^p\right]. \]The Stochastic Integral as a Continuous Martingale
Theorem 3.2.3 (Martingale Property and Continuity). Let \(f \in V_{[0,T]}\). The process
\[ M_t = \int_0^t f_s \, dB_s, \quad t \in [0, T], \]has a continuous modification which is an \(\mathcal{F}_t\)-martingale. Moreover, for any \(\lambda > 0\),
\[ P\!\left(\sup_{0 \leq t \leq T} |M_t| \geq \lambda\right) \leq \frac{1}{\lambda^2} \, E\!\left(\int_0^T f_s^2 \, ds\right). \]Proof. Choose elementary \((\varphi_n)\) with \(\|\varphi_n - f\|_V \to 0\). Each \(M_t^{(n)} = \int_0^t \varphi_n \, dB\) is a continuous martingale. By Doob’s maximal inequality and the Itô isometry:
\[ P\!\left(\sup_t |M_t^{(n+1)} - M_t^{(n)}| \geq 2^{-k}\right) \leq 4^k \|\varphi_{n+1} - \varphi_n\|_V^2. \]Passing to a fast-converging subsequence and applying Borel–Cantelli, we obtain \(\sup_t |M_t^{(n_{k+1})} - M_t^{(n_k)}| \leq 2^{-k}\) for all large \(k\), a.s. Thus \(M^{(n_k)}\) converges uniformly to a continuous limit \(M_t\). This limit agrees in \(L^2\) with \(\int_0^t f \, dB\) and inherits the martingale property by \(L^2\) convergence of conditional expectations. The maximal bound follows from Doob’s inequality applied to \(M\) and the Itô isometry. \(\blacksquare\)
3.3 Extensions
Stochastic Integral with Stopping Time
Theorem 3.3.1 (Stopped Integral). Let \(f \in V_{[0,T]}\) and \(\tau\) a stopping time with \(\tau \leq T\). Then
\[ \int_0^\tau f_s \, dB_s = \int_0^T f_s \, \mathbf{1}_{\{s < \tau\}} \, dB_s \quad \text{a.s.} \]This result is the gateway to localization: it allows us to extend the stochastic integral to processes that are only locally square-integrable, by stopping at times where the integrability condition holds.
Multidimensional Itô Integral
For an \(n\)-dimensional Brownian motion \(B = (B^1, \ldots, B^n)\) and an \(m \times n\) matrix process \(f = (f_{ik})\) with entries in \(V\), the stochastic integral is the \(\mathbb{R}^m\)-valued process with \(i\)-th component
\[ \left(\int_0^t f \, dB\right)_i = \sum_{k=1}^n \int_0^t f_{ik}(s) \, dB_s^k. \]Weakened Integrability and Local Martingales
When only \(P(\int_0^T f_s^2 \, ds < \infty) = 1\) holds (rather than \(E(\int f^2 \, ds) < \infty\)), define stopping times \(\tau_n = \inf\{t : \int_0^t f^2 \, ds \geq n\} \wedge T\). Then \(\tau_n \nearrow T\) a.s., and \(f \cdot \mathbf{1}_{[0, \tau_n)} \in V\) for each \(n\). The stochastic integrals are consistent, giving a well-defined process \(M_t = \int_0^t f \, dB\) that is a local martingale — each stopped process \(M^{\tau_n}\) is a true martingale.
Definition 3.3.2 (Local Martingale). An adapted continuous process \((X_t)\) is a local martingale if there exist stopping times \(\tau_n \nearrow \infty\) a.s. such that \((X_{t \wedge \tau_n})\) is a martingale for each \(n\).
3.4 Itô Processes and Itô’s Formula
Itô Processes
Definition 3.4.1 (Itô Process). An adapted process \(X_t\) is an Itô process if
\[ X_t = X_0 + \int_0^t u_s \, ds + \int_0^t v_s \, dB_s, \]where \(u\) (the drift) satisfies \(\int_0^T |u_s| \, ds < \infty\) a.s. and \(v\) (the diffusion) satisfies \(\int_0^T v_s^2 \, ds < \infty\) a.s. In differential notation: \(dX_t = u_t \, dt + v_t \, dB_t\).
Itô’s Formula
Theorem 3.4.2 (Itô’s Formula). Let \(dX_t = u_t \, dt + v_t \, dB_t\) and \(g \in C^{1,2}([0,\infty) \times \mathbb{R})\). Then \(Y_t = g(t, X_t)\) is an Itô process with
\[ dY_t = \frac{\partial g}{\partial t}(t, X_t) \, dt + \frac{\partial g}{\partial x}(t, X_t) \, dX_t + \frac{1}{2} \frac{\partial^2 g}{\partial x^2}(t, X_t) \, v_t^2 \, dt. \]The extra second-order term is the Itô correction, arising from the formal rules \((dB_t)^2 = dt\), \((dt)^2 = dt \cdot dB_t = 0\).
The Itô correction is the essential difference between stochastic and classical calculus. It arises because Brownian motion accumulates non-trivial quadratic variation: in any time interval \([0, t]\), the sum of squared increments converges to \(t\), not to zero.
Example: Geometric Brownian Motion
Let \(\sigma, r\) be constants and consider
\[ X_t = X_0 \exp\!\left(\left(r - \tfrac{\sigma^2}{2}\right)t + \sigma B_t\right). \]Applying Itô’s formula with \(g(z) = X_0 e^z\) to the Itô process \(Z_t = (r - \sigma^2/2)t + \sigma B_t\):
\[ dX_t = X_t\left[\left(r - \tfrac{\sigma^2}{2}\right)dt + \sigma \, dB_t\right] + \tfrac{1}{2} X_t \sigma^2 \, dt = rX_t \, dt + \sigma X_t \, dB_t. \]The drift correction \(-\sigma^2/2\) in the exponent is precisely compensated by the Itô correction \(+\sigma^2/2\), yielding the clean SDE \(dX_t = rX_t \, dt + \sigma X_t \, dB_t\). This is the geometric Brownian motion, fundamental in mathematical finance as the Black–Scholes model.
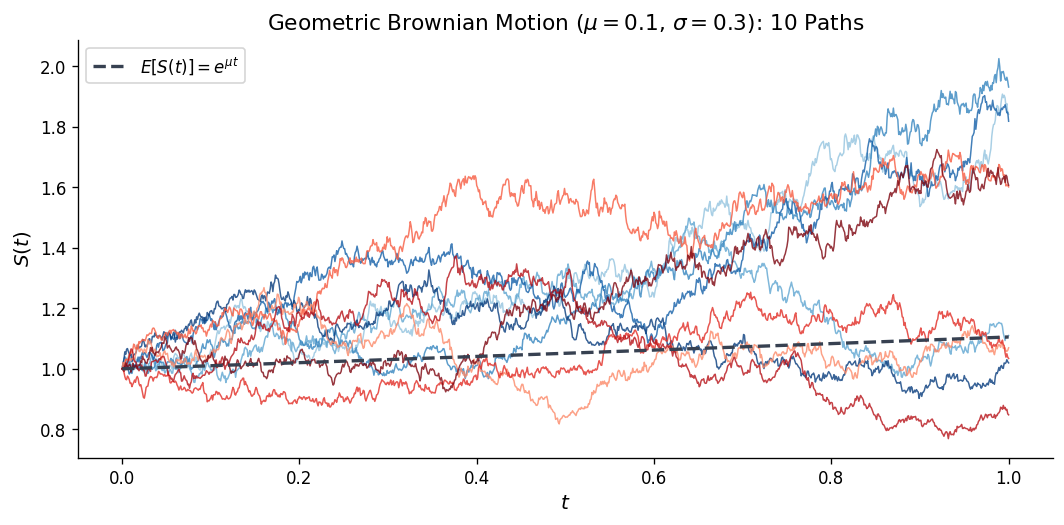
Integration by Parts
Theorem 3.4.3 (Itô Integration by Parts). Let \(dX_t = u_1 \, dt + v_1 \, dB_t\) and \(dY_t = u_2 \, dt + v_2 \, dB_t\). Then
\[ d(X_t Y_t) = X_t \, dY_t + Y_t \, dX_t + v_1 v_2 \, dt. \]Equivalently,
\[ \int_0^t X_s \, dY_s = X_t Y_t - X_0 Y_0 - \int_0^t Y_s \, dX_s - \int_0^t v_1(s) v_2(s) \, ds. \]Proof. Apply Itô’s formula to \(g(x, y) = xy\). Since \(g_{xx} = g_{yy} = 0\) and \(g_{xy} = 1\), the formula gives \(d(XY) = Y \, dX + X \, dY + dX \cdot dY\), where \(dX \cdot dY = v_1 v_2 (dB)^2 = v_1 v_2 \, dt\). Alternatively, one computes \(d(X+Y)^2 - d(X-Y)^2\) and uses the polarization identity. \(\blacksquare\)
The cross-variation term \(v_1 v_2 \, dt\) is the stochastic correction to the classical product rule. When one factor is deterministic (\(v = 0\)), the correction vanishes and we recover the classical formula.
Chapter 4: Continuous Semimartingales and Quadratic Variation
4.1 Quadratic variation of Brownian motion
In the previous chapters we assembled the machinery of martingale theory and conditional expectation. We now turn to a phenomenon that lies at the heart of stochastic calculus: quadratic variation. Classical calculus rests on the fact that a smooth path \(f\) on \([a,b]\) has vanishing quadratic variation — the sum \(\sum |f(t_{i+1}) - f(t_i)|^2\) tends to zero as the partition mesh shrinks. Brownian motion is fundamentally different.
![Quadratic variation: [W,W]_t = t vs. smooth function](/pics/stat902/quadratic_variation.png)
Its paths are so rough that the analogous sum converges to a non-zero, deterministic limit. Understanding this limit is the key to unlocking the Ito calculus.
Let \((B_t)_{t \ge 0}\) be a standard Brownian motion on a filtered probability space \((\Omega, \mathcal{F}, (\mathcal{F}_t), \mathbb{P})\). Fix an interval \([a, b]\), and let \(\Delta = \{a = t_0 < t_1 < \cdots < t_n = b\}\) be a partition with mesh \(|\Delta| = \max_i (t_{i+1} - t_i)\).
Theorem 4.1 (Quadratic variation of Brownian motion). As \(|\Delta| \to 0\),
\[ \sum_{i=0}^{n-1} (B_{t_{i+1}} - B_{t_i})^2 \;\longrightarrow\; b - a \quad \text{in } L^2(\mathbb{P}). \]The convergence is not merely in probability — it holds in mean square. This is a consequence of the independent increments of Brownian motion and the explicit computability of the fourth moment of a Gaussian.
Proof. Write \(\Delta_i B = B_{t_{i+1}} - B_{t_i}\) and set \(S_\Delta = \sum_{i=0}^{n-1} (\Delta_i B)^2\). Since increments are independent and \(\Delta_i B \sim \mathcal{N}(0, t_{i+1} - t_i)\), we have \(\mathbb{E}\left[(\Delta_i B)^2\right] = t_{i+1} - t_i\), so \(\mathbb{E}\left[S_\Delta\right] = b - a\). It remains to show \(\operatorname{Var}(S_\Delta) \to 0\). By independence,
\[ \operatorname{Var}(S_\Delta) = \sum_{i=0}^{n-1} \operatorname{Var}\!\left((\Delta_i B)^2\right). \]For a centered Gaussian \(Z \sim \mathcal{N}(0, \sigma^2)\), one computes \(\mathbb{E}\left[Z^4\right] = 3\sigma^4\), so \(\operatorname{Var}(Z^2) = 3\sigma^4 - \sigma^4 = 2\sigma^4\). Applying this with \(\sigma^2 = t_{i+1} - t_i\):
\[ \operatorname{Var}(S_\Delta) = 2 \sum_{i=0}^{n-1} (t_{i+1} - t_i)^2 \;\le\; 2 |\Delta| \sum_{i=0}^{n-1} (t_{i+1} - t_i) = 2|\Delta|(b-a) \;\longrightarrow\; 0. \]Thus \(S_\Delta \to b - a\) in \(L^2\). ∎
This result immediately yields a fundamental martingale identity. Since the quadratic variation of Brownian motion on \([0, t]\) is \(t\), the process \(B_t^2 - t\) “removes” the accumulated variance, leaving a martingale.
Corollary 4.2. The process \(B_t^2 - t\) is a continuous martingale with respect to the natural filtration of \(B\).
Proof. By direct computation: for \(s \le t\),
\[ \mathbb{E}\left[B_t^2 - t \mid \mathcal{F}_s\right] = \mathbb{E}\left[(B_t - B_s + B_s)^2 \mid \mathcal{F}_s\right] - t = \mathbb{E}\left[(B_t - B_s)^2\right] + 2 B_s \mathbb{E}\left[B_t - B_s\right] + B_s^2 - t = (t-s) + B_s^2 - t = B_s^2 - s. \]Continuity follows from that of \(B\). ∎
4.2 A key structural lemma: continuous finite-variation martingales vanish
Before constructing the quadratic variation of a general continuous martingale, we establish a lemma that will be used repeatedly throughout the theory. It asserts that the only continuous martingale whose paths have finite variation is the zero process. This rigidity result is what forces us to develop stochastic integration theory rather than simply using the Lebesgue–Stieltjes integral.
Lemma 4.3 (Continuous FV martingale lemma). Let \(M\) be a continuous local martingale with \(M_0 = 0\). If \(M\) has paths of finite variation on compacts almost surely, then \(M_t = 0\) for all \(t \ge 0\) almost surely.
Proof sketch. If \(M\) is a continuous martingale of finite variation, then its quadratic variation computed along partitions converges to zero (because the mesh times the total variation vanishes), while on the other hand it must equal \(\mathbb{E}\left[M_t^2\right]\) by the martingale property. Thus \(\mathbb{E}\left[M_t^2\right] = 0\), giving \(M_t = 0\) a.s. for each \(t\). Continuity upgrades this to simultaneous vanishing. ∎
This lemma is the engine behind all uniqueness results for quadratic variation. Whenever we need to show that two candidate quadratic-variation processes agree, we verify that their difference is a continuous martingale of finite variation.
4.3 Existence of quadratic variation for \(L^2\)-bounded continuous martingales
We now generalize Theorem 4.1 from Brownian motion to arbitrary \(L^2\)-bounded continuous martingales. The construction is more delicate because we can no longer exploit independent Gaussian increments. Instead, the martingale property itself provides the necessary orthogonality.
Let \(M = (M_t)_{t \ge 0}\) be a continuous martingale with \(\sup_t \mathbb{E}\left[M_t^2\right] < \infty\), and assume \(M_0 = 0\). For a partition \(\Delta = \{0 = t_0 < t_1 < \cdots < t_n = t\}\), define the truncated quadratic variation
\[ T_t^\Delta(M) = \sum_{i=0}^{k-1} (M_{t_{i+1}} - M_{t_i})^2 + (M_t - M_{t_k})^2, \]where \(t_k\) is the largest partition point at most \(t\). Notice that \(T_t^\Delta(M)\) is defined for every \(t \ge 0\), not just at partition points.
Theorem 4.4 (Existence and uniqueness of quadratic variation). Let \(M\) be a continuous \(L^2\)-bounded martingale with \(M_0 = 0\). There exists a unique continuous, increasing, adapted process \(\left[M\right]\) with \(\left[M\right]_0 = 0\) such that \(M^2 - \left[M\right]\) is a uniformly integrable martingale.
The proof proceeds through several steps. We outline each one, following Rutar’s presentation.
Proof.
Step 1: \(L^2\) convergence of \(T_t^\Delta(M)\).
The key identity is that for \(s \le t\),
\[ \mathbb{E}\left[T_t^\Delta(M) - T_s^\Delta(M) \mid \mathcal{F}_s\right] = \mathbb{E}\left[M_t^2 - M_s^2 \mid \mathcal{F}_s\right]. \]This follows because the cross-terms in the expansion of \(\sum (M_{t_{i+1}} - M_{t_i})^2\) vanish by the martingale property: if \(s \le t_i < t_{i+1}\), then \(\mathbb{E}\left[(M_{t_{i+1}} - M_{t_i})(M_{t_i} - M_{t_j}) \mid \mathcal{F}_{t_i}\right] = 0\). As a consequence, the map \(\Delta \mapsto T_t^\Delta(M)\) is Cauchy in \(L^2\): for two partitions \(\Delta\) and \(\Delta'\), one refines both and uses the identity above to control \(\mathbb{E}\left[(T_t^\Delta(M) - T_t^{\Delta'}(M))^2\right]\). The \(L^2\) limit as \(|\Delta| \to 0\) defines \(\left[M\right]_t\).
Step 2: Continuity.
By Doob’s maximal inequality applied to the \(L^2\) martingale \(T_t^\Delta(M) - \left[M\right]_t\), we upgrade pointwise \(L^2\) convergence to uniform convergence in probability on compact intervals. Since each \(T_t^\Delta(M)\) is a continuous function of \(t\) (because \(M\) is continuous), the limit \(\left[M\right]\) has a continuous modification.
Step 3: \(\left[M\right]\) is increasing.
For \(s < t\), the identity from Step 1 gives
\[ \mathbb{E}\left[\left[M\right]_t - \left[M\right]_s \mid \mathcal{F}_s\right] = \mathbb{E}\left[M_t^2 - M_s^2 \mid \mathcal{F}_s\right] = \mathbb{E}\left[(M_t - M_s)^2 \mid \mathcal{F}_s\right] \ge 0. \]Since \(\left[M\right]_t - \left[M\right]_s\) is a limit of non-negative sums, it is non-negative a.s.
Step 4: \(M^2 - \left[M\right]\) is a martingale.
We have \(T_t^\Delta(M) \to \left[M\right]_t\) in \(L^2\), and from the telescoping identity
\[ M_t^2 = T_t^\Delta(M) + 2 \sum_{i} (M_{t_i} - M_0)(M_{t_{i+1}} - M_{t_i}) + \text{boundary terms}, \]the identity \(\mathbb{E}\left[M_t^2 - T_t^\Delta(M) \mid \mathcal{F}_s\right] = M_s^2 - T_s^\Delta(M)\) passes to the limit, establishing the martingale property for \(M^2 - \left[M\right]\).
Step 5: Uniform integrability.
The martingale \(M^2 - \left[M\right]\) is \(L^1\)-bounded (since \(M\) is \(L^2\)-bounded and \(\mathbb{E}\left[\left[M\right]_t\right] = \mathbb{E}\left[M_t^2\right] \le C\)), so by the martingale convergence theorem it converges a.s. and in \(L^1\), which gives uniform integrability.
Step 6: Uniqueness.
Suppose \(A\) is another process with the stated properties. Then \(\left[M\right] - A\) is a continuous martingale (difference of two processes for which \(M^2\) minus the process is a UI martingale) and has paths of finite variation (difference of two increasing processes). By Lemma 4.3, \(\left[M\right]_t = A_t\) for all \(t\) a.s. ∎
4.4 Generalization via localization
The \(L^2\)-boundedness assumption can be relaxed by localization. For any continuous martingale \(M\), define the stopping times
\[ T_n = \inf\{t \ge 0 : |M_t| \ge n\}. \]By continuity, \(T_n \uparrow \infty\) a.s. The stopped process \(M^{T_n}\) is a continuous \(L^2\)-bounded martingale (bounded by \(n\)), so Theorem 4.4 applies and provides \(\left[M^{T_n}\right]\). By uniqueness, these are consistent: \(\left[M^{T_n}\right]_t = \left[M^{T_m}\right]_t\) for \(t \le T_n\) when \(n \le m\). Patching together, we obtain a process \(\left[M\right]\) defined globally.
Corollary 4.5. Every continuous local martingale \(M\) with \(M_0 = 0\) admits a unique continuous increasing process \(\left[M\right]\) with \(\left[M\right]_0 = 0\) such that \(M^2 - \left[M\right]\) is a local martingale.
The quadratic variation \(\left[M\right]\) is a non-random clock that measures the “intrinsic time” of the martingale. For Brownian motion, \(\left[B\right]_t = t\), recovering Theorem 4.1. For a time-changed Brownian motion \(M_t = B_{\tau(t)}\), we get \(\left[M\right]_t = \tau(t)\). The quadratic variation encodes all the second-order information about the martingale.
Chapter 5: Local Martingales and the Stochastic Exponential
With the quadratic variation in hand, we now build the full stochastic integration theory. This chapter proceeds in five stages: we first study local martingales and the class DL condition that characterizes when a local martingale is a true martingale, then introduce quadratic covariation, construct the stochastic integral, derive the general Ito formula for semimartingales, and finally study the stochastic exponential and Levy’s characterization of Brownian motion.
5.1 Local martingales and class DL
Recall that a local martingale is an adapted cadlag process \(M\) for which there exist stopping times \(T_n \uparrow \infty\) such that each stopped process \(M^{T_n} = (M_{t \wedge T_n})_{t \ge 0}\) is a uniformly integrable martingale. Every martingale is trivially a local martingale (take \(T_n = n\)), but the converse fails in general. The question of when a local martingale is a true martingale is both theoretically important and practically delicate.
Definition 5.1 (Class DL). An adapted process \(X\) is of class DL if for every \(a > 0\), the family
\[ \{X_T : T \text{ is a stopping time with } 0 \le T \le a\} \]is uniformly integrable.
The class DL condition is a uniform integrability requirement indexed not merely by deterministic times but by all bounded stopping times. It is a strong regularity condition that prevents the local martingale from “hiding mass at infinity” via clever stopping.
Theorem 5.2. A continuous local martingale \(M\) is a (true) martingale if and only if it is of class DL.
Proof. (\(\Rightarrow\)) Suppose \(M\) is a continuous martingale. Fix \(a > 0\) and let \(S, T\) be stopping times with \(0 \le S \le T \le a\). By the optional sampling theorem for UI martingales, \(\mathbb{E}\left[M_T \mid \mathcal{F}_S\right] = M_S\). The family \(\{M_T : 0 \le T \le a\}\) is uniformly integrable because it equals the family \(\{\mathbb{E}\left[M_a \mid \mathcal{F}_T\right] : 0 \le T \le a\}\), which is UI by a standard conditional expectation lemma (Lemma 5.3 below).
(\(\Leftarrow\)) Suppose \(M\) is a continuous local martingale of class DL. Let \(T_n \uparrow \infty\) be the localizing sequence. For any bounded stopping time \(T \le a\), the stopped times \(T \wedge T_n\) satisfy \(M_{T \wedge T_n} \to M_T\) a.s. by continuity. The class DL condition gives uniform integrability, so \(L^1\) convergence holds. For \(s \le t\) and \(A \in \mathcal{F}_s\),
\[ \mathbb{E}\left[M_t \mathbf{1}_A\right] = \lim_n \mathbb{E}\left[M_{t \wedge T_n} \mathbf{1}_A\right] = \lim_n \mathbb{E}\left[M_{s \wedge T_n} \mathbf{1}_A\right] = \mathbb{E}\left[M_s \mathbf{1}_A\right], \]establishing the martingale property. ∎
The forward direction used the following standard fact about conditional expectations.
Lemma 5.3. If \(X \in L^1\) and \((\mathcal{G}_\alpha)_{\alpha \in I}\) is any family of sub-\(\sigma\)-algebras of \(\mathcal{F}\), then the family \(\{\mathbb{E}\left[X \mid \mathcal{G}_\alpha\right] : \alpha \in I\}\) is uniformly integrable.
Proof. By Jensen’s inequality, \(|\mathbb{E}\left[X \mid \mathcal{G}_\alpha\right]| \le \mathbb{E}\left[|X| \mid \mathcal{G}_\alpha\right]\), so it suffices to treat \(X \ge 0\). For any \(c > 0\),
\[ \mathbb{E}\left[\mathbb{E}\left[X \mid \mathcal{G}_\alpha\right] \mathbf{1}_{\{\mathbb{E}\left[X \mid \mathcal{G}_\alpha\right] > c\}}\right] \le \mathbb{E}\left[X \mathbf{1}_{\{\mathbb{E}\left[X \mid \mathcal{G}_\alpha\right] > c\}}\right]. \]By Markov’s inequality, \(\mathbb{P}(\mathbb{E}\left[X \mid \mathcal{G}_\alpha\right] > c) \le \mathbb{E}\left[X\right]/c \to 0\) as \(c \to \infty\), uniformly in \(\alpha\). Since \(X\) is integrable, the integral of \(X\) over sets of vanishing measure tends to zero, giving the UI property uniformly. ∎
With Theorem 5.2 in hand, we can complete the proof that \(M^2 - \left[M\right]\) is a uniformly integrable martingale for \(L^2\)-bounded \(M\). Indeed, by Doob’s maximal inequality, \(\mathbb{E}\left[\sup_{s \le t} M_s^2\right] \le 4 \mathbb{E}\left[M_t^2\right]\), so the family \(\{M_T^2 : T \le a\}\) is uniformly integrable (dominated by \(\sup_{s \le a} M_s^2 \in L^1\)). Since \(\left[M\right]_T \le \left[M\right]_a\) for \(T \le a\) and \(\mathbb{E}\left[\left[M\right]_a\right] = \mathbb{E}\left[M_a^2\right] < \infty\), the family \(\{M_T^2 - \left[M\right]_T : T \le a\}\) is uniformly integrable. By Theorem 5.2, the local martingale \(M^2 - \left[M\right]\) is a true martingale, and indeed a UI martingale.
5.2 Quadratic covariation
For two continuous local martingales \(M\) and \(N\), we define their quadratic covariation (or cross-variation) by the polarization identity.
Definition 5.4 (Quadratic covariation). For continuous local martingales \(M\) and \(N\),
\[ \left[M, N\right] = \frac{1}{4}\left(\left[M + N\right] - \left[M - N\right]\right). \]This is the unique continuous finite-variation process vanishing at zero such that \(MN - \left[M, N\right]\) is a local martingale. Uniqueness follows from Lemma 4.3, just as for the quadratic variation. The polarization identity reduces all covariation computations to variation computations.
By expanding, one sees that the quadratic covariation also equals the limit of cross-variation sums:
\[ \left[M, N\right]_t = \lim_{|\Delta| \to 0} \sum_{i} (M_{t_{i+1}} - M_{t_i})(N_{t_{i+1}} - N_{t_i}), \]with convergence in probability. The bilinearity is immediate: \(\left[M, N\right]\) is bilinear in \((M, N)\), symmetric, and satisfies \(\left[M, M\right] = \left[M\right]\).
Proposition 5.5. For continuous local martingales \(M, N\) with \(M_0 = N_0 = 0\), the process \(M_t N_t - \left[M, N\right]_t\) is a continuous local martingale.
5.3 Stochastic integration for local martingales
We now construct the stochastic integral \(\int H \, dM\), first for simple integrands, then extending to a rich class of predictable processes. The construction parallels the way one builds the Lebesgue integral: start with step functions, establish an isometry, and extend by density.
Elementary integrands
Definition 5.6 (Elementary integrand). An elementary integrand is a process of the form
\[ H_t(\omega) = Z(\omega) \cdot \mathbf{1}_{(S(\omega), T(\omega)]}(t), \]where \(S \le T\) are stopping times and \(Z\) is a bounded \(\mathcal{F}_S\)-measurable random variable.
For such an \(H\), the stochastic integral is defined pointwise:
\[ (H \cdot M)_t = \int_0^t H_s \, dM_s = Z\left(M_{T \wedge t} - M_{S \wedge t}\right). \]This is a natural definition: \(H\) prescribes holding \(Z\) units of the martingale during the time interval \((S, T]\). The integral records the resulting gains.
Proposition 5.7. If \(M\) is a continuous \(L^2\)-bounded martingale and \(H\) is an elementary integrand, then \(H \cdot M\) is a continuous \(L^2\)-bounded martingale.
Proof. Adaptedness and continuity are immediate. For the martingale property, take \(s \le t\) and compute
\[ \mathbb{E}\left[(H \cdot M)_t \mid \mathcal{F}_s\right] = \mathbb{E}\left[Z(M_{T \wedge t} - M_{S \wedge t}) \mid \mathcal{F}_s\right]. \]By the optional sampling theorem (since \(M\) is UI), \(\mathbb{E}\left[M_{T \wedge t} \mid \mathcal{F}_{T \wedge s}\right] = M_{T \wedge s}\), and similarly for \(S\). Using the tower property and \(\mathcal{F}_S\)-measurability of \(Z\), one obtains \(Z(M_{T \wedge s} - M_{S \wedge s}) = (H \cdot M)_s\). The \(L^2\) bound follows from \(\|Z\|_\infty < \infty\) and \(\sup_t \mathbb{E}\left[M_t^2\right] < \infty\). ∎
By linearity, the integral extends to linear combinations of elementary integrands. We denote the collection of such processes by \(\mathcal{E}\).
The \(L^2(M)\) space and the isometry
To extend beyond simple integrands, we introduce the appropriate Hilbert space.
Definition 5.8 (\(L^2(M)\) space). For a continuous \(L^2\)-bounded martingale \(M\), define
\[ L^2(M) = \left\{H \text{ predictable} : \mathbb{E}\!\left[\int_0^\infty H_s^2 \, d\left[M\right]_s\right] < \infty\right\}. \]The predictable \(\sigma\)-algebra \(\mathcal{P}\) on \(\left[0, \infty\right) \times \Omega\) is the \(\sigma\)-algebra generated by the elementary integrands. Crucially, every adapted cadlag process is predictable (and in fact every adapted left-continuous process is predictable). This makes the class of predictable processes very rich.
The fundamental analytical tool is the Ito isometry.
Theorem 5.9 (Ito isometry). For \(H \in \mathcal{E}\) (linear combinations of elementary integrands) and \(M\) a continuous \(L^2\)-bounded martingale,
\[ \mathbb{E}\left[(H \cdot M)_\infty^2\right] = \mathbb{E}\!\left[\int_0^\infty H_s^2 \, d\left[M\right]_s\right]. \]Proof. It suffices to check this for a single elementary integrand \(H = Z \cdot \mathbf{1}_{(S,T]}\). Then
\[ (H \cdot M)_\infty = Z(M_T - M_S), \]and
\[ \mathbb{E}\left[Z^2(M_T - M_S)^2\right] = \mathbb{E}\left[Z^2 \cdot \mathbb{E}\left[(M_T - M_S)^2 \mid \mathcal{F}_S\right]\right] = \mathbb{E}\left[Z^2\left(\left[M\right]_T - \left[M\right]_S\right)\right] = \mathbb{E}\!\left[\int_0^\infty H_s^2 \, d\left[M\right]_s\right], \]where we used the fact that \(M^2 - \left[M\right]\) is a martingale and the \(\mathcal{F}_S\)-measurability of \(Z\). Bilinearity extends the identity to \(\mathcal{E}\). ∎
The isometry tells us that the stochastic integral \(H \mapsto H \cdot M\) is an isometric linear map from \(\mathcal{E}\) (with the \(L^2(M)\) norm) into the space of \(L^2\)-bounded martingales (with the \(L^2(\mathbb{P})\) norm at infinity). Since \(\mathcal{E}\) is dense in \(L^2(M)\) (this is proved via the monotone class theorem, using the fact that the elementary integrands generate the predictable \(\sigma\)-algebra), the integral extends uniquely to all of \(L^2(M)\) by continuity.
Theorem 5.10 (Stochastic integral for \(L^2\) integrands). There exists a unique continuous linear extension of the map \(H \mapsto H \cdot M\) from \(L^2(M)\) to the space of continuous \(L^2\)-bounded martingales, preserving the isometry
\[ \mathbb{E}\left[(H \cdot M)_\infty^2\right] = \mathbb{E}\!\left[\int_0^\infty H_s^2 \, d\left[M\right]_s\right]. \]Moreover, \(\left[H \cdot M\right]_t = \int_0^t H_s^2 \, d\left[M\right]_s\).
Extension by localization
To handle integrands that are not globally \(L^2\), we localize. A process \(H\) is locally bounded predictable (denoted \(\mathrm{lbP}\)) if there exist stopping times \(T_n \uparrow \infty\) with \(H \cdot \mathbf{1}_{\left[0, T_n\right]}\) bounded for each \(n\). Similarly, \(\mathcal{M}^2_{0,\mathrm{loc}}\) denotes the space of continuous local martingales vanishing at zero.
For \(H \in \mathrm{lbP}\) and \(M \in \mathcal{M}^2_{0,\mathrm{loc}}\), one defines \(H \cdot M\) by localization: choose \(T_n\) such that both \(H \cdot \mathbf{1}_{\left[0, T_n\right]}\) is bounded and \(M^{T_n}\) is \(L^2\)-bounded. The integrals \((H \cdot \mathbf{1}_{\left[0, T_n\right]}) \cdot M\) are consistent by uniqueness, and their common extension defines \(H \cdot M \in \mathcal{M}^2_{0,\mathrm{loc}}\).
5.4 Semimartingales and the general Ito formula
Semimartingales
Definition 5.11 (Semimartingale). A continuous semimartingale is a process of the form
\[ X_t = X_0 + M_t + A_t, \]where \(X_0\) is \(\mathcal{F}_0\)-measurable, \(M\) is a continuous local martingale with \(M_0 = 0\), and \(A\) is a continuous adapted process of finite variation with \(A_0 = 0\).
By Lemma 4.3, this decomposition is unique. The martingale part \(M\) captures the “noise” and the finite-variation part \(A\) captures the “drift.” For a semimartingale \(X = X_0 + M + A\) and a locally bounded predictable process \(H\), the stochastic integral is
\[ (H \cdot X)_t = (H \cdot M)_t + \int_0^t H_s \, dA_s, \]where the first term is the stochastic integral constructed above and the second is a pathwise Lebesgue–Stieltjes integral.
Integration by parts
The following integration-by-parts formula is the bridge between quadratic variation and the Ito formula.
Theorem 5.12 (Integration by parts). If \(X\) and \(Y\) are continuous semimartingales, then
\[ X_t Y_t = X_0 Y_0 + \int_0^t X_s \, dY_s + \int_0^t Y_s \, dX_s + \left[X, Y\right]_t. \]In particular, taking \(X = Y = M\) (a continuous local martingale):
\[ M_t^2 = 2 \int_0^t M_s \, dM_s + \left[M\right]_t, \]which recovers Corollary 4.2 for Brownian motion. Taking \(X = M\) and \(Y = V\) where \(V\) is of finite variation (so \(\left[M, V\right] = 0\)):
\[ M_t V_t = \int_0^t M_s \, dV_s + \int_0^t V_s \, dM_s. \]Several useful algebraic identities follow.
Proposition 5.13. Let \(M, N\) be continuous local martingales and \(H, K\) locally bounded predictable processes. Then:
- \(\left[H \cdot M, K \cdot N\right]_t = \int_0^t H_s K_s \, d\left[M, N\right]_s\).
- \((H \cdot M)^T = H \cdot \mathbf{1}_{(0,T]} \cdot M = H \cdot M^T\) for any stopping time \(T\).
- \(H \cdot (K \cdot M) = (HK) \cdot M\) (associativity of stochastic integration).
Property (1) shows how quadratic covariation transforms under stochastic integration — the integrands simply multiply under the bracket. Property (3) is the associativity that makes the stochastic integral well-behaved as a functional calculus.
The general Ito formula
We now state the crown jewel of stochastic calculus.
Theorem 5.14 (Ito’s formula, general version). Let \(X = (X^1, \ldots, X^n)\) be an \(\mathbb{R}^n\)-valued continuous semimartingale and \(f \in C^2(\mathbb{R}^n)\). Then
\[ f(X_t) - f(X_0) = \sum_{i=1}^n \int_0^t \partial_i f(X_s) \, dX_s^i + \frac{1}{2} \sum_{i,j=1}^n \int_0^t \partial_i \partial_j f(X_s) \, d\left[X^i, X^j\right]_s. \]The first sum is the “classical” chain rule term, while the second sum — the Ito correction — arises from the non-vanishing quadratic variation of the martingale parts. In classical calculus, this term would be zero because smooth paths have zero quadratic variation.
Proof sketch (Stone–Weierstrass argument). Let \(\mathcal{A}\) be the collection of all \(C^2\) functions \(f: \mathbb{R}^n \to \mathbb{R}\) for which Ito’s formula holds. We verify:
\(\mathcal{A}\) contains all polynomials. For the identity \(f(x) = x_i\), the formula reduces to the tautology \(X_t^i - X_0^i = \int dX_s^i\). For \(f(x) = x_i x_j\), the formula is exactly the integration-by-parts formula (Theorem 5.12). Higher-degree monomials follow by induction and the product rule.
\(\mathcal{A}\) is an algebra. If \(f, g \in \mathcal{A}\), then \(fg \in \mathcal{A}\) follows from the product rule and the bilinearity of the bracket.
\(\mathcal{A}\) separates points and contains the constants. This is clear since it contains the coordinate functions and the constant function \(1\).
\(\mathcal{A}\) is closed under local uniform limits of functions together with their first two derivatives. This follows because all terms in the formula depend continuously on \(f\) and its derivatives.
By the Stone–Weierstrass theorem, polynomials are dense in \(C^2\) on compact sets (in the topology of uniform convergence of the function and its first two derivatives). Since semimartingale paths stay in compact sets on finite time intervals, the formula extends from polynomials to all of \(C^2(\mathbb{R}^n)\). ∎
5.5 The stochastic exponential and Levy’s characterization
The Doleans-Dade exponential
Given a continuous semimartingale \(X\) with \(X_0 = 0\), we seek the process \(Z\) satisfying the stochastic differential equation
\[ dZ_t = Z_t \, dX_t, \quad Z_0 = 1. \]In ordinary calculus, this would be \(Z_t = e^{X_t}\). In stochastic calculus, the Ito correction modifies the answer.
Definition 5.15 (Doleans-Dade exponential). The stochastic exponential of a continuous semimartingale \(X\) with \(X_0 = 0\) is
\[ \mathcal{E}(X)_t = \exp\!\left(X_t - \frac{1}{2}\left[X\right]_t\right). \]Theorem 5.16. The process \(Z_t = \mathcal{E}(X)_t\) is the unique continuous semimartingale satisfying
\[ Z_t = 1 + \int_0^t Z_s \, dX_s. \]Proof of existence. Apply Ito’s formula (Theorem 5.14) to \(f(x, y) = e^{x - y/2}\) with arguments \(X_t\) and \(\left[X\right]_t\). Writing \(Z_t = f(X_t, \left[X\right]_t)\):
\[ dZ_t = \partial_x f \, dX_t + \partial_y f \, d\left[X\right]_t + \frac{1}{2}\partial_{xx} f \, d\left[X\right]_t + \frac{1}{2}\partial_{yy} f \, d\left[X, X\right]_t + \partial_{xy} f \, d\left[X, \left[X\right]\right]_t. \]Since \(\left[X\right]\) is of finite variation, \(\left[\left[X\right], \left[X\right]\right] = 0\) and \(\left[X, \left[X\right]\right] = 0\). Computing derivatives: \(\partial_x f = f\), \(\partial_y f = -f/2\), \(\partial_{xx} f = f\). Thus
\[ dZ_t = Z_t \, dX_t - \frac{1}{2} Z_t \, d\left[X\right]_t + \frac{1}{2} Z_t \, d\left[X\right]_t = Z_t \, dX_t, \]and \(Z_0 = e^{0 - 0} = 1\).
Proof of uniqueness. Suppose \(\tilde{Z}\) also satisfies the equation. Define \(Y_t = Z_t^{-1}\) (note \(Z_t > 0\) since it is an exponential). By Ito’s formula applied to \(g(z) = 1/z\):
\[ dY_t = -Z_t^{-2} \, dZ_t + \frac{1}{2} \cdot 2 Z_t^{-3} \, d\left[Z\right]_t = -Y_t \, dX_t + Y_t \, d\left[X\right]_t. \]Now apply integration by parts to \(\tilde{Z}_t Y_t\):
\[ d(\tilde{Z}_t Y_t) = \tilde{Z}_t \, dY_t + Y_t \, d\tilde{Z}_t + d\left[\tilde{Z}, Y\right]_t. \]Since \(d\tilde{Z}_t = \tilde{Z}_t \, dX_t\) and \(d\left[\tilde{Z}, Y\right]_t = \tilde{Z}_t Y_t(-1) \, d\left[X\right]_t\) (from the integrand identity, Proposition 5.13(1)):
\[ d(\tilde{Z}_t Y_t) = \tilde{Z}_t Y_t\left(-dX_t + d\left[X\right]_t + dX_t - d\left[X\right]_t\right) = 0. \]So \(\tilde{Z}_t Y_t = \tilde{Z}_0 Y_0 = 1\) for all \(t\), hence \(\tilde{Z}_t = Z_t\). ∎
The stochastic exponential is the natural notion of “exponential” in the stochastic world. Note that \(\mathcal{E}(X)\) is always strictly positive. When \(X = \sigma B\) for a Brownian motion \(B\) and constant \(\sigma\), we get \(\mathcal{E}(\sigma B)_t = \exp(\sigma B_t - \sigma^2 t/2)\), which is the fundamental exponential martingale of mathematical finance (the density process in the Girsanov theorem).
Levy’s characterization of Brownian motion
We conclude with a remarkable converse: Brownian motion is completely characterized by two properties — being a continuous local martingale and having quadratic variation equal to \(t\). No reference to Gaussian distributions or independence is needed.
Theorem 5.17 (Levy’s characterization). Let \(B\) be a continuous local martingale with \(B_0 = 0\) and \(\left[B\right]_t = t\) for all \(t \ge 0\). Then \(B\) is a standard Brownian motion.
Proof. We show that \(B\) has the correct characteristic function. Fix \(\theta \in \mathbb{R}\) and define
\[ M_t^\theta = \exp\!\left(i\theta B_t + \frac{\theta^2}{2} t\right). \]We claim \(M^\theta\) is a continuous local martingale. Apply Ito’s formula to \(f(x) = e^{i\theta x}\) and the semimartingale \(B\):
\[ df(B_t) = i\theta e^{i\theta B_t} \, dB_t + \frac{1}{2}(i\theta)^2 e^{i\theta B_t} \, d\left[B\right]_t = i\theta e^{i\theta B_t} \, dB_t - \frac{\theta^2}{2} e^{i\theta B_t} \, dt. \]Now apply Ito’s formula to \(g(x, y) = x \cdot e^{y}\) with \(x = e^{i\theta B_t}\) and \(y = \theta^2 t/2\):
\[ dM_t^\theta = e^{\theta^2 t/2} \, d(e^{i\theta B_t}) + e^{i\theta B_t} \cdot \frac{\theta^2}{2} e^{\theta^2 t/2} \, dt + 0. \]Substituting:
\[ dM_t^\theta = e^{\theta^2 t/2}\!\left(i\theta e^{i\theta B_t} \, dB_t - \frac{\theta^2}{2} e^{i\theta B_t} \, dt\right) + \frac{\theta^2}{2} M_t^\theta \, dt = i\theta M_t^\theta \, dB_t. \]The drift terms cancel, so \(M^\theta\) is a continuous local martingale. Since \(|M_t^\theta| = e^{\theta^2 t/2}\) is deterministic, \(M^\theta\) is in fact a bounded martingale on \(\left[0, T\right]\) for every \(T\). Thus \(\mathbb{E}\left[M_t^\theta\right] = M_0^\theta = 1\), which gives
\[ \mathbb{E}\left[e^{i\theta B_t}\right] = e^{-\theta^2 t/2}. \]This is the characteristic function of \(\mathcal{N}(0, t)\). Since characteristic functions determine distributions, \(B_t \sim \mathcal{N}(0, t)\).
For independence of increments, apply the same argument to \(B_t - B_s\) conditional on \(\mathcal{F}_s\): the process \(M_t^\theta / M_s^\theta\) is a martingale on \(\left[s, \infty\right)\), which gives \(\mathbb{E}\left[e^{i\theta(B_t - B_s)} \mid \mathcal{F}_s\right] = e^{-\theta^2(t-s)/2}\). The conditional characteristic function is deterministic, so \(B_t - B_s\) is independent of \(\mathcal{F}_s\) and has distribution \(\mathcal{N}(0, t-s)\). ∎
Levy’s characterization is a cornerstone of stochastic analysis. It is the principal tool for verifying that a given process is a Brownian motion — one need only check continuity, the local martingale property, and \(\left[B\right]_t = t\). It plays a central role in the Girsanov theorem, in the theory of stochastic differential equations, and in the martingale characterization of diffusion processes.
References
These notes follow the treatment in:
Rutar, Alex. “Martingales and Stochastic Calculus.” Student notes, University of Waterloo, Winter 2020. The primary source for the organization, theorem statements, and proof strategies of Chapters 4 and 5.
Heunis, Andrew J. “Notes on Stochastic Calculus: E&CE 784, STAT 902.” University of Waterloo, 2011. Supplementary reference for the measure-theoretic foundations and the treatment of local martingales and class DL.
The following standard references provide further depth and alternative perspectives on the material:
Revuz, Daniel, and Marc Yor. Continuous Martingales and Brownian Motion. 3rd ed., Springer, 1999. The encyclopedic reference for continuous martingale theory, quadratic variation, and stochastic calculus.
Karatzas, Ioannis, and Steven E. Shreve. Brownian Motion and Stochastic Calculus. 2nd ed., Springer, 1991. A thorough and widely-used graduate text covering the full development from Brownian motion through stochastic differential equations.
Le Gall, Jean-Francois. Brownian Motion, Martingales, and Stochastic Calculus. Springer, 2016. A modern and concise treatment emphasizing the martingale approach to stochastic integration, closely aligned with the presentation in these notes.